<목차>
1. ODQA란
2. Passage Retrieval - Sparse Embedding
3. Passage Retrieval - Dense Embedding
QA(Question Answering)
다양한 종류의 질문에 대해 대답하는 인공지능을 만드는 연구 분야
Open-Domain Question Answering (ODQA)
주어지는 지문이 따로 존재하지 않고 사전에 구축되어있는 Knowledge resource 에서 질문에 대답할 수 있는 문서를 찾는다.

two stage: 1. 질문에 관련된 문서를 찾아주는 "retriever"
2. 관련된 문서를 읽고 적절한 답변을 찾거나 만들어주는 "reader"
Passage Retrieval
질문(query)에 맞는 문서(passage)를 찾는 것
Query와 Passage를 임베딩한 뒤 유사도로 랭킹을 매기고, 유사도가 가장 높은 Passage를 선택한다.
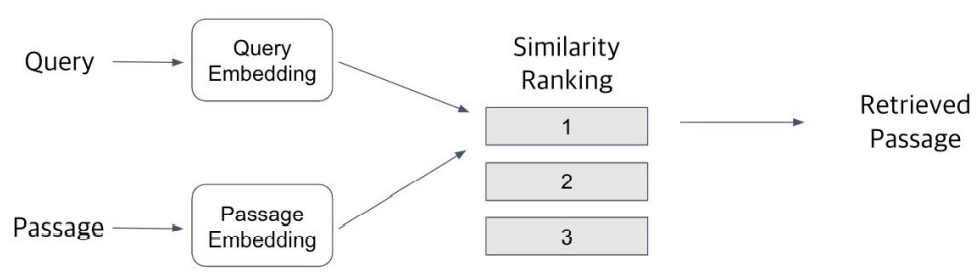
이렇게 Passage Embedding의 벡터 공간을 'Passage Embedding Space'라고 한다. 벡터화된 Passage를 이용하여 Passage 간 유사도 등을 계산할 수 있다.
Sparse Embedding
기존 연구에서는 Retrieval 하기 위해서 inverted index를 활용해 키워드를 기반으로 탐색하는 TF-IDF나 BM25같은 고차원의 sparse representing을 사용하였다.
<Sparse Embedding의 방법들>
1. BoW를 구성하는 방법 (n-gram)
– unigram (1-gram): It was the best of times => It, was, the, best, of, time
– bigram (2-gram): It was the best of times => It was, was the, the best, best of, of times
2. Term value 를 결정하는 방법
– Term이 document에 등장하는지 (binary)
– Term이 몇번 등장하는지 (term frequency), 등. (e.g. TF-IDF)
<Sparse Embedding의 특징>
1. Dimension of embedding vector = number of terms
– 등장하는 단어가 많아질수록 증가
– N-gram의 n이 커질수록 증가
2. Term overlap을 정확하게 잡아 내야 할 때 유용하다.
3. 반면, 의미(semantic)가 비슷하지만 다른 단어인 경우 비교가 불가하다.
<Sparse Embedding의 한계>
1. 차원의 수가 매우 크다 => compressed format으로 극복 가능
2. 유사성을 고려하지 못한다
Sparse Retrieval는 휴리스틱하게 문서를 검색하는 기법이라면 Dense Retrieval는 Retriever를 학습을 통해 최적화를 한다.
Question : "Who is the bad guy in lord of the rings?"
위 질문에 대한 답변은 "Sala Baker is an actor and stuntman from New Zealand. He is best known for portraying the villain Sauron in the Lord of the Rings”라는 context에서 찾을 수 있을 것이다.
Sparse retrieval의 경우는 동의어나 paraphrase한 context에 대해서 유사하다고 판단할 수 없기 때문에 해당 문서를 관련 문서로 판단하지 못한다. 그러나 Dense Retrieval은 "bad guy"와 "villain"이 유사한 의미임을 semantic하게 판단할 수 있기 때문에 해당 문서를 관련 문서로 판단할 수 있다.
| Sparse | Dense |
| 1. 중요한 term들이 정확히 일치해야 하는 경우 성능이 뛰어나다. 2. 임베딩이 구축되고 나서는 추가적인 학습이 불가능하다. |
1. 단어의 유사성 또는 맥락을 파악해야 하는 경우 성능이 뛰어나다. 2. 학습을 통해 임베딩을 만들며, 추가적인 학습이 가능하다. |
[참고]
BM25, TF-IDF와 같은 sparse retreival의 문제점을 해결하기 위해 ORQA, REALM과 같은 BM25보다 성능이 좋은 dense representation 방식이 제안되었으나, 이 방식들은 학습 과정이 너무 복잡하고 비용이 비싸다.
또한, 기존 ORQA는 passage encoder를 train 할 때 passage에서 text를 추출하는 방식으로 진행하며, 이 방법이 question과 passage의 관계를 정확하게 파악하게 할 수 있을지가 불분명하다.
ORQA 🤢
Retrieval를 Inverse Cloze Task(ICT)로 unsupervised pretraining을 수행한다.
(finetuning 시 빠르게 Wikipedia를 인코딩하고 supurious ambiguity를 피하도록 bias를 부여하기 위한 목적)
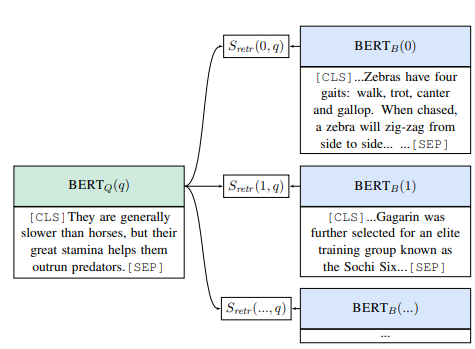
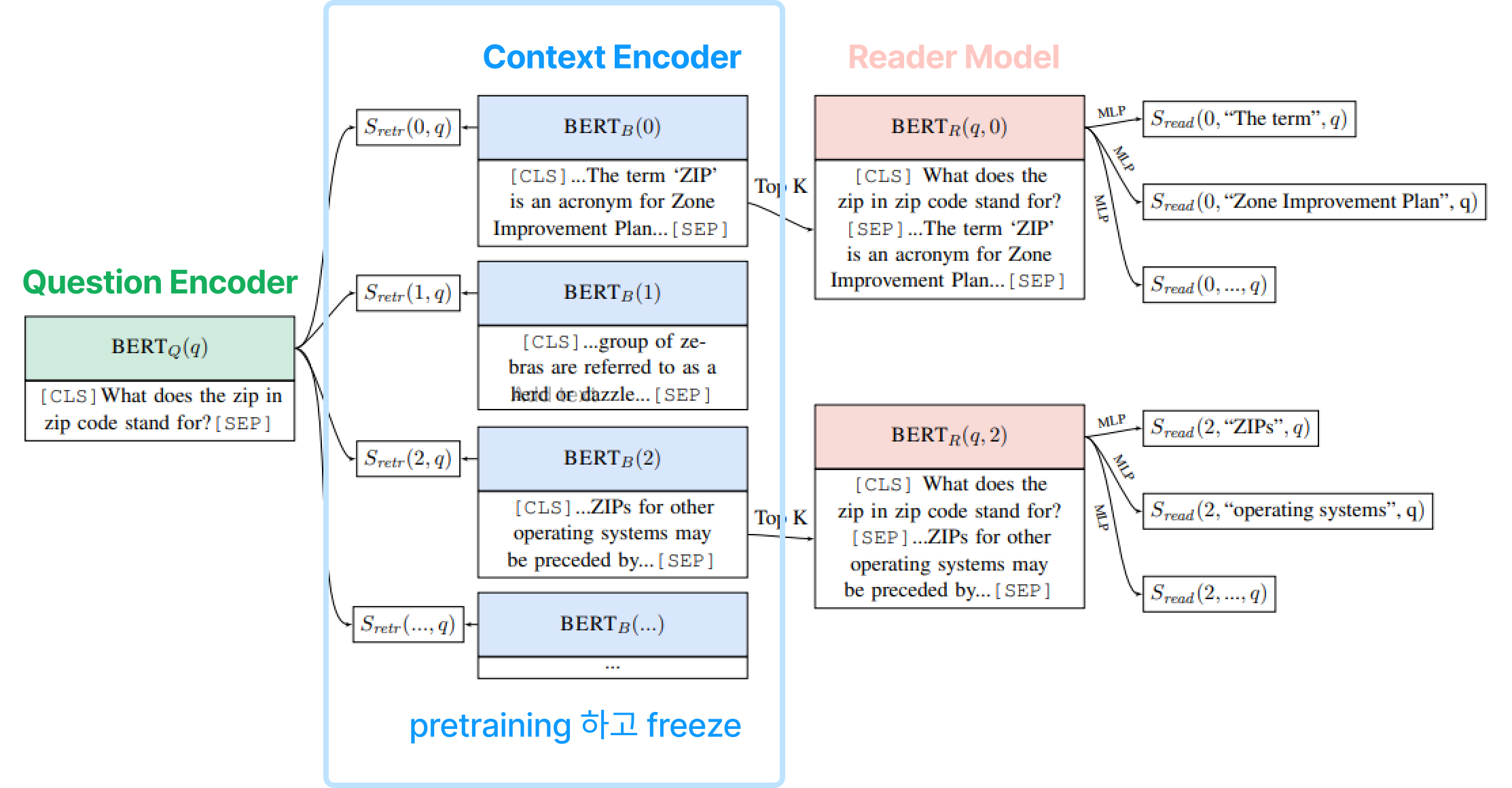
<ORQA의 한계점>
- Pretraining 과정에서의 계산량이 많다.
- ICT는 Passage에서 임의로 문장을 추출하고(Pseudo Question) 이 문장에 대한 유사한 passage를 retrieve하도록 하는 사전학습 형태인데 해당 Pseudo Question은 사실상 Question이라고 볼 수 없다.
- 위 그림에서처럼 Context Encoder는 freezing하기 때문에 QA task에 있어서 optimial한 representation이 아니다.
ORQA보다 비용이 저렴하면서도 BM25의 한계를 극복할 수 있는 Dense representation 방식이 DPR이다.
Dense Embedding, Dense Passage Retrieval(DPR)
context의 sementic한 정보를 인코딩하여 dense vector로 표현하는 기법은 sparse representation을 보완하는 역할을 한다.
<Dense Embedding의 특징>
– 더 작은 차원의 고밀도 벡터 (length = 50-1000)
– 각 차원이 특정 term에 대응되지 않는다.
– 대부분의 요소가 non-zero값이다.
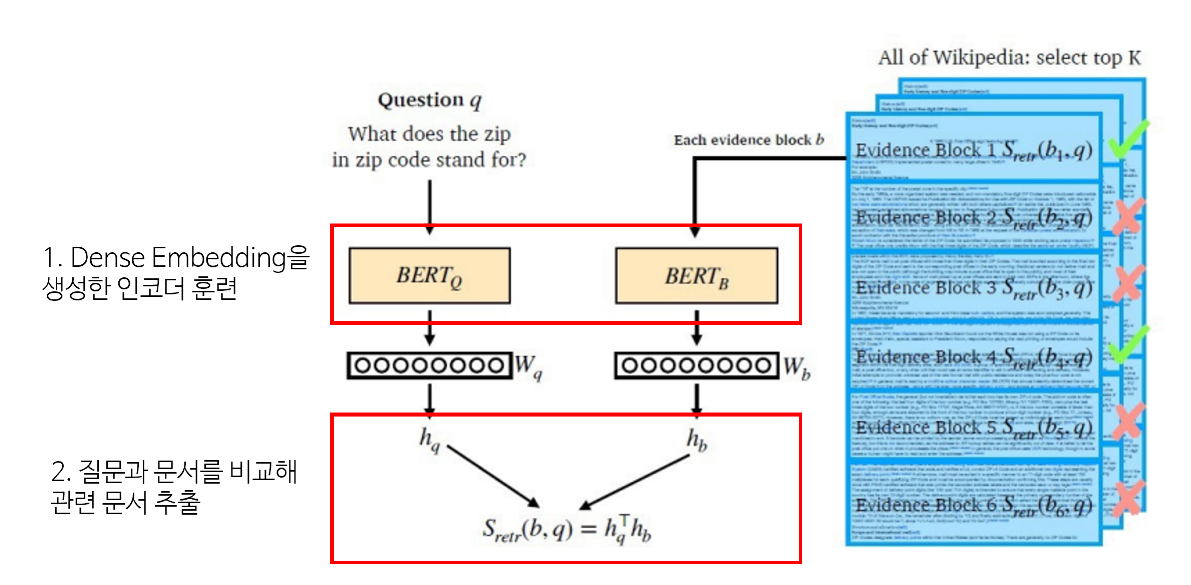
주로 BERT와 같은 PLM이 자주 사용된다.
Dense Encoder의 구조를 살펴보면 다음과 같다.
사전 학습된 BERT로 이루어진 두 개의 Encoder를 사용해 각각 Question과 Passage를 encoding하고, Question과 Passage간의 유사도는 dot product로 계산한다.
Question과 Passage간의 유사도를 측정하는데 있어서 신경망을 사용할 수도 있지만, Passage의 Embedding 계산이 사전에 계산될 수 있도록 유사도 함수는 기능적으로 분해성이 있을 필요가 있다. 분해성이 있는 유사도 함수로는 dot product 외에도 L2, Cosine Similarity도 있지만 성능은 비슷했기 때문에 간단한 연산인 dot product를 선택하였다.
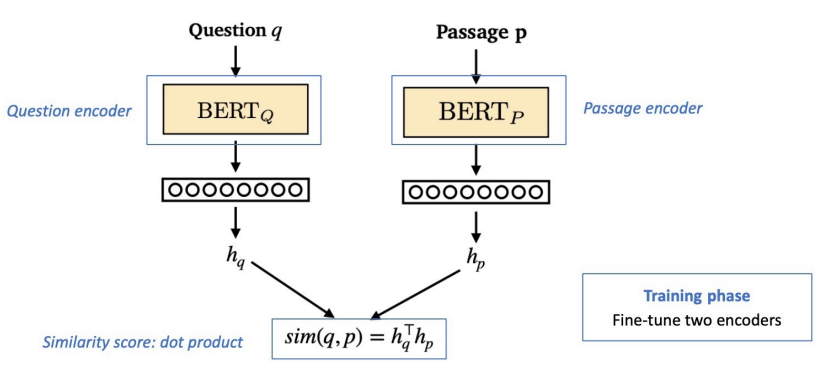
- 학습목표는 "연관된 question과 passage dense embedding 간의 거리를 좁히는 것 (또는 inner product를 높이는 것)"이다. 즉, 유사도를 높이려고 한다.
이를 위해 Negative Sampling을 활용할 수 있다. 높은 TF-IDF 값을 가지지만 답을 포함하지 않는 샘플처럼 Negative Sample을 추출할 수 있다.
- Objective function으로는 "Positive passage 에 대한 negative log likelihood (NLL) loss"를 사용한다.

- "연관된 question/passage를 어떻게 찾을 것인가?"의 challenge의 해결책으로, 기존 MRC 데이터 셋을 활용하고자 한다.
- Inference 시에는, Passage와 query를 각각 embedding한 후, query로부터 가까운 순서대로 passage의 순서를 매긴다.
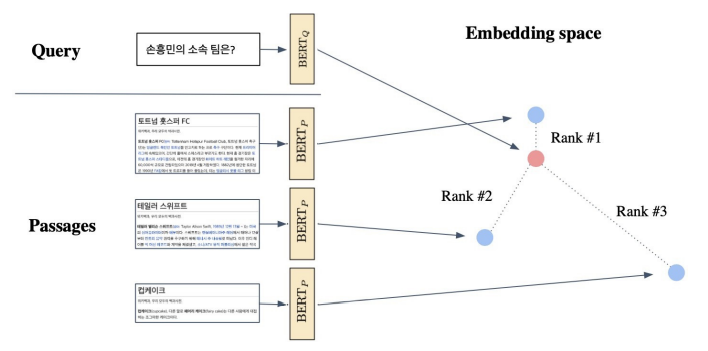
<Dense encoding의 성능을 높이기 위한 방법>
- 학습 방법 개선 (e.g. DPR)
- 인코더 모델 개선 (BERT보다 큰, 정확한 Pretrained 모델)
- 데이터 개선 (더 많은 데이터, 전처리, 등)
Dense Passage Retrieval 평가지표
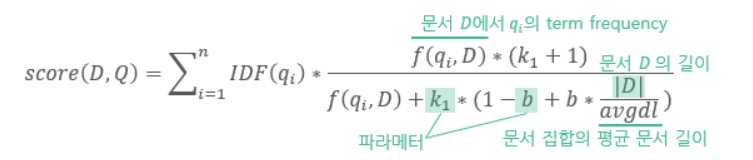
BM25 (키워드 기반의 랭킹 알고리즘)
Bag-of-words 개념을 사용하여 쿼리에 있는 용어가 각각의 문서에 얼마나 자주 등장하는지를 평가한다.
TF-IDF와 같이 주어진 쿼리에 대한 문서들의 연관성을 측정하는 함수이다.
TF-IDF와 다른 점은 TF를 사용하지 않고 문서 전체 길이를 반영한다는 점이다.
Passage Retrieval - Scaling up
검색하는 과정을 빠르게 하는 방법으로 "Similarity Search"가 있다.
MIPS(Maximum Inner Product Search)
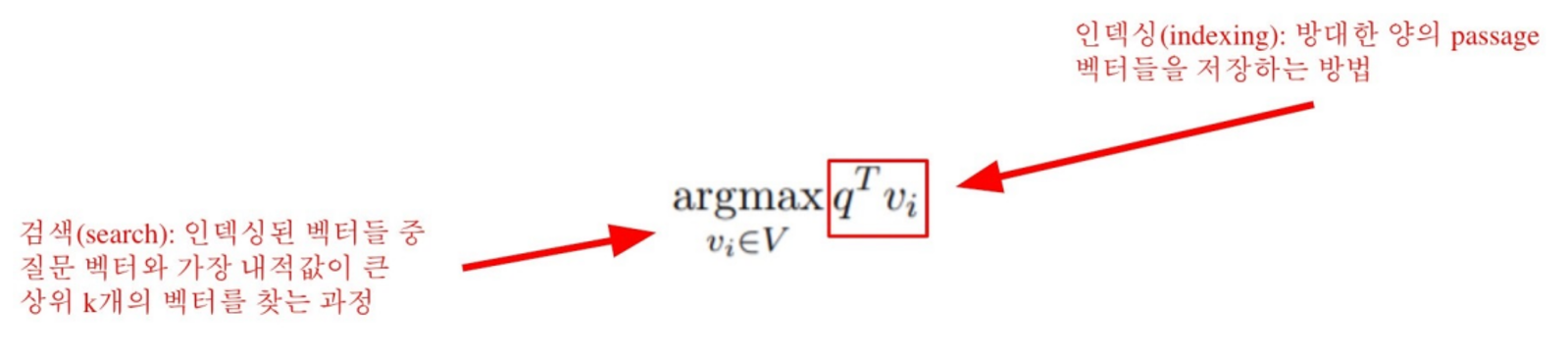
이전까지 사용된 brute-force(exhaustive) search는 저장해둔 모든 sparse/dense 임베딩에 대해 일일히 내적값을 계산해서 값이 가장 큰 passage를 추출한다.
하지만 실제 데이터의 양은 훨씬 방대하므로, 이렇게 문서 임베딩을 일일히 보면서 검색할 수는 없다.
그래서 등장한 방법이 "Similarity Search"이다. 📣📣📣
물론 아래와 같은 trade-off가 존재한다. 속도(search time)과 재현율(recall) 사이의 trade-off가 있다. 즉, 더 정확한 검색을 하려면 더 오랜 시간이 걸린다.


Similarity Search - Compression
vector을 압축하여 하나의 vector가 적은 용량을 차지한다. 메모리는 줄어드나 정보 손실이 증가한다.
ex. scalar quantization : 4-byte floating point => 1 byte unsigned integer

Pruning - Inverted File(IVF)
Search space를 줄여서 search 속도를 개선한다. 즉, dataset의 subset(일부)만 방문한다.
clustering과 inverted file을 활용한 search 두 가지 방법이 사용된다.
1. clustering : 전체 vector space를 k개의 cluster로 나눈다 (ex. k-means clustering)
2. IVF : vector의 index가 inverted list 구조를 가진다. 즉, 각 cluster의 centroid id와 해당 cluster의 vector들이 연결되어 있는 상태이다.
다음과 같이 step 1. 주어진 query vector에 대한 근접한 centroid 벡터를 찾는다 => step 2. 찾은 cluster의 inverted list 내 vector들에 대해 서치를 수행한다.

📣📣📣 FAISS
FAISS는 효율적인 similariy search와 dense vector의 clustering을 돕는 라이브러리이다.
index를 train하는 과정과 더하는 과정 두 단계로 나뉜다. train 과정이 필요한 이유는 quantize할 때 큰 값을 0~255로 압축하나까
비율, offset 알아야 하기 때문이다.


'AI TECH' 카테고리의 다른 글
| Fast API (1) (1) | 2023.01.12 |
|---|---|
| Product Serving (1) | 2023.01.12 |
| MRC (0) | 2022.12.20 |
| 언어모델 실습 (1) | 2022.11.24 |
| Docker (0) | 2022.11.11 |