'지문(Context)이 주어질 때 주어진 질의(Query/Question)의 답변을 추론하는 문제'이다.
<MRC Dataset 종류>
- Extractive Answer Datasets : 지문에서 답변을 추출한다 (답변이 항상 context의 segment(span)에 존재) 분류 문제(classification)로 취급한다
📣 Step1 pre-process Pre-process 단계에서 Attention mask는 다음과 같다. 입력 시퀀스 중 Attention 연산을 할 때 무시할 토큰을 0으로 표시한다. 즉, 1은 연산에 포함된다. 보통은 [PAD]와 같은 의미 없는 특수기호 토큰을 무시하기 위해 사용한다.
입력이 2개 이상의 sequence일 때 (ex. 질문과 지문), 각각 ID를 부여해 모델이 구분되어 해석하도록 유도한다.
정답은 문서 내 존재하는 연속된 단어토큰(span)이므로, 모델 출력값으로는 답안을 생성하기보다는 span의 시작과 끝 위치를 예측하도록 학습한다. (= Token classification 문제로 치환해서 생각한다)
📣 Step2 Fine-tuning Fine-tuning BERT를 살펴보자
📣 Step3 Post-processing (1) 불가능한 답을 제거하고, (2) 최적의 답안을 찾는다.
(1) 아래의 경우를 제거할 수 있다. - End가 Start보다 앞에 있는 경우 - 예측한 위치가 context를 벗어난 경우 (ex. question 위치에 답이 나온 경우) - 미리 설정한 max_answer_length보다 긴 경우
(2) 최적의 답안을 찾는 과정은 다음과 같다. - start/end position prediction에서 score(logits)가 가장 높은 N개를 각각 찾는다. - 불가능한 조합들을 제거하고, 가능한 조합의 score 합을 큰 순서대로 정렬한다. - Top-k가 필요한 경우, 차례대로 내보낸다.
- Descriptive/Narrative Answer Datasets : 문제를 보고 답변을 생성 생성문제(generation) 문제로 취급한다.
📣 Extraction-based와의 차이점 1. 모델 구조 Extraction-based는 PLM + Classifier 구조인 반면, Generation-based는 Seq-to-seq PLM 구조이다.
2. Loss 계산을 위한 답 형태 / Prediction 형태 Extraction-based는 지문 내 답의 위치를 반환하고, Generation-based는 Free-form text 형태로 반환한다.
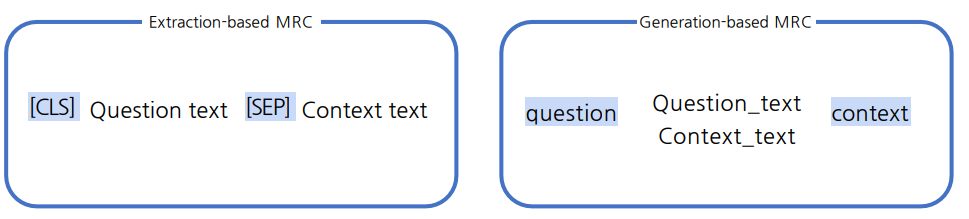
3. Preprocessing 과정에서 Special Token Extraction-based는 CLS, SEP, PAD 토큰을 사용하고, Generation-based는 이 외에도 자연어를 이용하여 정채진 텍스트 포맷(format)으로 데이터를 생성하기도 한다. 4. Preprocessing 과정에서 입력 표현 (additional information) Attention mask는 동일하다. 하지만 Token type ids에서, BART는 BERT와 달리 입력 시퀀스에 대한 구분이 없어서 token_type_ids가 존재하지 않는다. 따라서 Generation-based에는 token_type_ids가 들어가지 않는다.
- Multiple-choice Datasets : 객관식
<MRC의 문제점>
- Paraphrasing : 같은 의미의 문장에 대한 이해가 필요하다
- Conference Resolution : 대명사가 어떤 대상을 지칭하는 가를 알아야 한다
- Unanswerable Question: 답변을 찾을 수 없는 경우, 억지 답변이 아닌 “No answer”이라는 선택지가 있어야 한다
- Multi-hop Reasoning: 답변을 찾기 위해 여러 개의 문서에서 supporting fact를 찾아야 하는 경우(ex: HotpotQA, QAngaroo)가 존재한다.
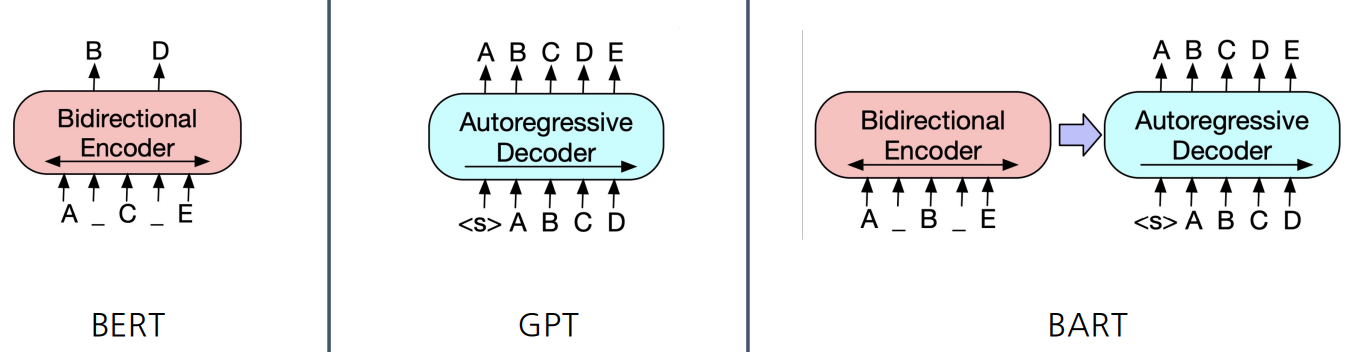
BART
기계독해, 기계 번역, 요약, 대화 등 sequence to sequence 문제의 pre-training을 위한 denoising autoencoder이다.