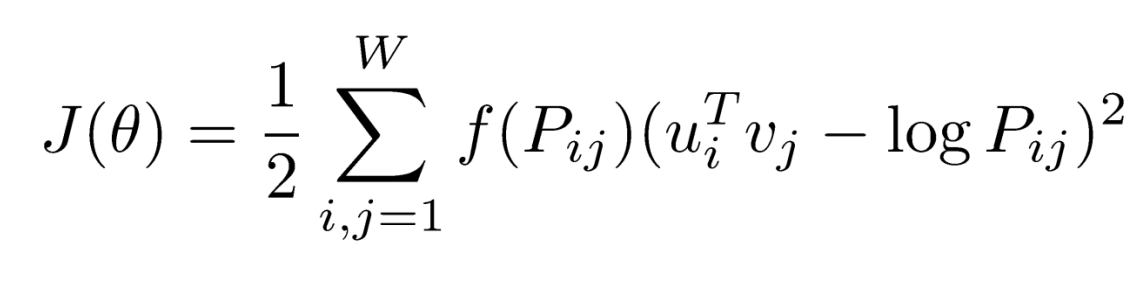비슷한 의미의 단어는 공간 상 가까운 위치에 맵핑하도록 하여 의미의 유사도를 잘 반영한다.
ex) cat과 kitty는 가까운 위치에, lemon은 먼 위치에
Word Embedding을 학습하는 대표적인 방법에는 Word2Vec과 GloVe가 있다.
Word2Vec
Word2Vec는 한 단어의 주변 단어를 통해 그 단어의 의미를 파악한다. (Skip-gram 방식)
과정을 세 단계로 크게 나눌 수 있다.
1. tokenization : 학습 데이터를 word별로 분리
2. unique한 단어들만 모아서 vocabulary 생성
3. sliding window라는 기법을 사용해 한 단어를 중심으로 앞 뒤의 단어로 입출력 단어 쌍을 이룸. 단어에 대한 dense vector을 얻을 수 있다.
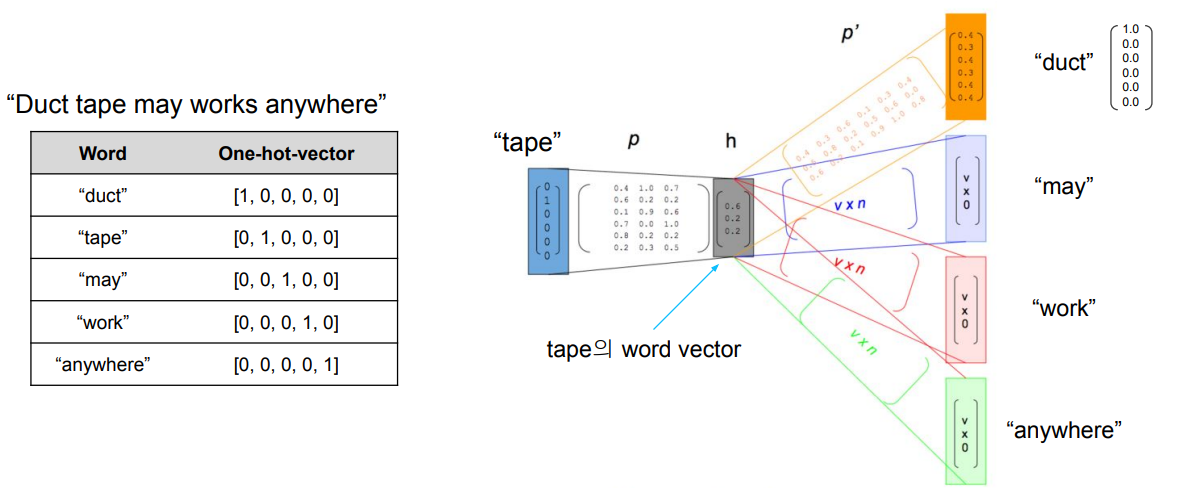
ex) 주어진 학습 데이터는 "I study math"라는 단 하나의 문장으로 구성되어 있다고 가정하자
vocabulary는 {"I", "study", "math"}
중심 단어
(입력, 출력) 중심 단어를 기준으로 왼쪽, 오른쪽
I
(I, study)
study
(study, I), (study, math)
math
(math, study)
이렇게 만들어진 입출력 단어쌍에 대해 예측 task를 수행하는 2 layer neural net을 만들자.
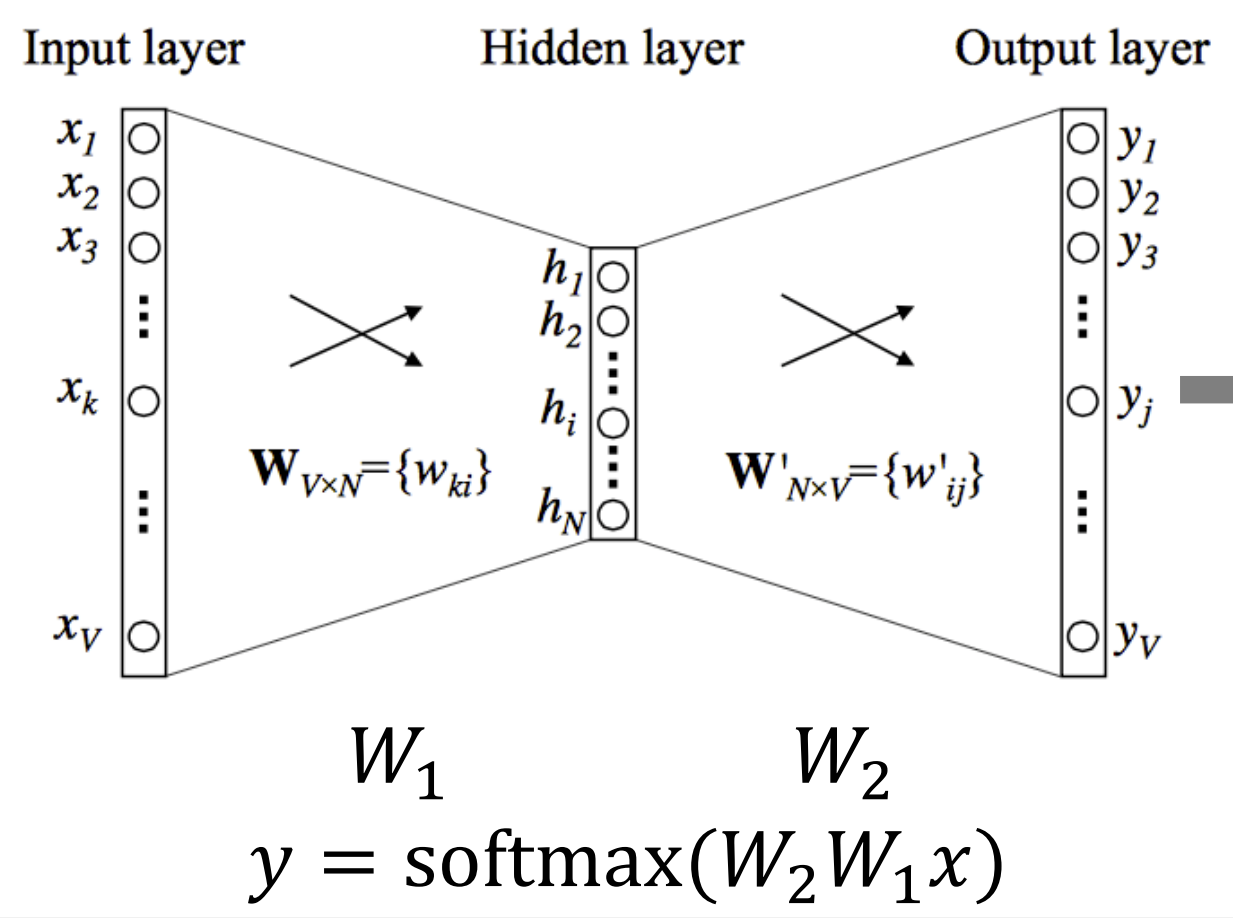
각 단어의 vocabulary size 만큼 one hot vactor로 나타나고, 위 예제에서는 3차원이므로 입출력 layer의 node 수는 3개이다.
가운데에 있는 hidden layer의 node 수는 사용자가 정하는 하이퍼 파라미터로서 word embedding을 수행하는 좌표공간의 차원수와 동일한 값으로 설정하게 된다.
(study, math)라는 입출력쌍을 가지고 예측을 하는 two layer Neural Network를 만들었다고 가정해보자.
원-핫 벡터로 변환한 벡터를 linear layer의 weight인 W1과 W2를 거친 뒤 softmax layer에 통과 시켜줌으로써 원하는 출력 값이 나오는 방향으로 학습하게 된다.
W1이 2*3 matrix인 이유는 입력값(input)의 3차원, 출력값(hidden)은 2차원이기 때문이다. W2가 3*2인 이유는 마찬가지로 입력값(input)의 2차원, 출력값(hidden)은 3차원이기 때문이다.
[과정 자세히 톺아보기]
1. 맨 처음으로 W1과 input vector와 행렬곱을 하게 되는데 이 과정에서 행렬곱을 모두 계산할 필요가 없다. 그 이유는 input vector의 1인 부분만 살아남기 때문이다. 즉, 원-핫 벡터의 1의 자리에 위치에 해당하는 W1의 column vector을 추출하는 과정을 embedding layer라고 부른다.
2. W2에서는 row vector의 수가 vocabulary 단어 수만큼 존재하고 W1의 column 벡터와 내적이 성립해야하므로 dimension이 동일하게 2이다.
3. softmax를 거쳐 나오는 확률분포가 ground-truth 확률분포와 최대한 유사하게 나오기 위해 softmax의 입력으로 들어가는 logit 값은 ground truth에 들어가는 값을 무한대, 아닌 값을 -무한대로 설정한다.
Word2Vec의 핵심
내적연산을 벡터들간의 유사도를 나타내는 과정으로 본다면
주어진 입력 단어의 W1상에서의 벡터와 주어진 출력단어의 W2상에서의 벡터간의 내적에 기반한 유사도가 최대한 커지는 방향으로 주어진 입력 단어의 W1상에서의 벡터와 주어진 출력단어가 아닌 단어의 W2상에서의 벡터간의 내적에 기반한 유사도가 최대한 작아지는 방향으로 파라미터를 학습해나간다
Word2Vec의 특징
장점
- 단어 간의 유사도 측정에 용이 - 단어 간의 관계 파악에 용이 - 벡터 연산을 통한 추론이 가능 (e.g. 한국 – 서울 + 도쿄 = ?)
단점
- 단어의 subword information 무시 (e.g. 서울 vs 서울시 vs 고양시) - Our of vocabulary (OOV)에서 적용 불가능
- FastText는 단어를 n-gram으로 분리를 한 후, 모든 n-gram vector를 합산한 후 평균을 통해 단어 벡터를 획득한다.
- 장점: 오탈자, OOV, 등장 회수가 적은 학습 단어에 대해서 강세
Training
-기존의 word2vec과 유사하나, 단어를 n-gram으로 나누어 학습을 수행 - n-gram의 범위가 2-5일 때, 단어를 다음과 같이 분리하여 학습함 ex. “assumption” = {as, ss, su, ….., ass, ssu, sum, ump, mpt,….., ption, assumption} - 이 때, n-gram으로 나눠진 단어는 사전에 들어가지 않으며, 별도의 n-gram vector를 형성함
Testing
- 입력 단어가 vocabulary에 있을 경우, word2vec과 마찬가지로 해당 단어의 word vector를 return함 - 만약 OOV일 경우, 입력 단어의 n-gram vector들의 합산을 return함
GloVe
GloVe는 Word2Vec와 다르게 각 입력 및 출력 단어쌍에 대해 같은 윈도우 내에서 얼마나 동시에 나타났는지를 미리 계산한다.
Loss function
ui는 입력 벡터, vi는 출력 벡터, Pij는 두 단어가 한 window 내에서 총 몇번 동시에 등장했는 가(확률)로 두개의 차이를 0으로 가까이 가게 하는 새로운 loss function을 사용한다.
Word2Vec 의 경우, 특정한 입출력 단어쌍이 자주 등장한 경우에 여러번에 걸처 학습됨으로써 word embedding vector간의 내적값이 학습 수에 비례해서 내적값이 더 커지도록하는 학습방식이라면
GloVe는 어떤 단어 쌍이 동시에 등장하는 횟수를 미리 계산하고 이에 대한 log 값을 취한 그 값을 직접적인 이 두 단어간의 내적값에 ground-truth 로써 사용해서 학습을 진행했다는 점에서 중복된 계산을 줄여줄 수 있다는 장점이 존재한다.
이러한 방법은 Word2Vec과 비교해서 중복 계산을 줄여주기 때문에 더 빠르며, 적은 데이터에서도 잘 동작한다.
GloVe도 Word2Vec와 동일하게 비슷한 관계끼리의 벡터가 동일한 모습을 확인할 수 있다.
💡
Text를 숫자로 변환하려는 시도에는 TF-IDF(Term Frequency-Inverse Document Frequency)도 있다
단어의 빈도와 역 문서 빈도를 사용하여 DTM 내의 각 단어들 마다 중요한 가중치를 변환한다.