
<목차>
1. Lambda
2. map
- replace
3. apply
- applymap
4. Built-in function
- describe
- unique
- isnull
- sort_values
- corr, cov, corrwith
Lambda argument: expression
- 한 줄로 함수를 표현하는 익명 함수 기법
'''
same as
def f(x,y);
return x+y
'''
f = lambda x,y:x+y
f(1,4)
하나의 argument만 처리하는 lambda 함수
f = lambda x:x/2
f(3) #1.5
이름을 할당하지 않는 lambda 함수
(lambda x:x+1)(5) #6map (function, sequence)
- 함수와 sequence형 데이터를 인자로 받아 각 element마다 입력받은 함수를 적용하여 list로 반환
- 일반적으로 함수를 lambda 형태로 표현
ex = [1,2,3,4,5]
f = lambda x: x**2
list(map(f,ex)) #[1,4,9,16,25]
두 개 이상의 argument가 있을 때는 두 개의 sequence 형을 써야함
f = lambda x, y: x+y
list(map(f,ex,ex))
익명 함수 그대로 사용가능
list(map(lambda x: x+x, ex))
map for series
ex1)
s1 = Series(np.arange(10))
s1.map(lambda x: x**2).head(5)
'''
0 0
1 1
2 4
3 9
4 16
dtype: int64
'''
dict type으로 데이터 교체, 없는 값은 NaN
z = {1: 'A', 2: 'B', 3: 'C'}
s1.map(z)
'''
0 NaN
1 A
2 B
3 C
4 NaN
5 NaN
6 NaN
7 NaN
8 NaN
9 NaN
dtype: object
'''
같은 위치의 데이터를 s2로 전환
s2 = Series(np.arange(10,20))
s1.map(s2)
'''
0 10
1 11
2 12
3 13
4 14
5 15
6 16
7 17
8 18
9 19
dtype: int32
'''
ex2)
df = pd.read_csv("wages.csv")
df.head()
df.sex.unique()
#array(['male', 'female'], dtype=object)
df["sex_code"] = df.sex.map({"male":0, "female":1})
replace
- map 함수의 기능 중 데이터 변환 기능만 담당
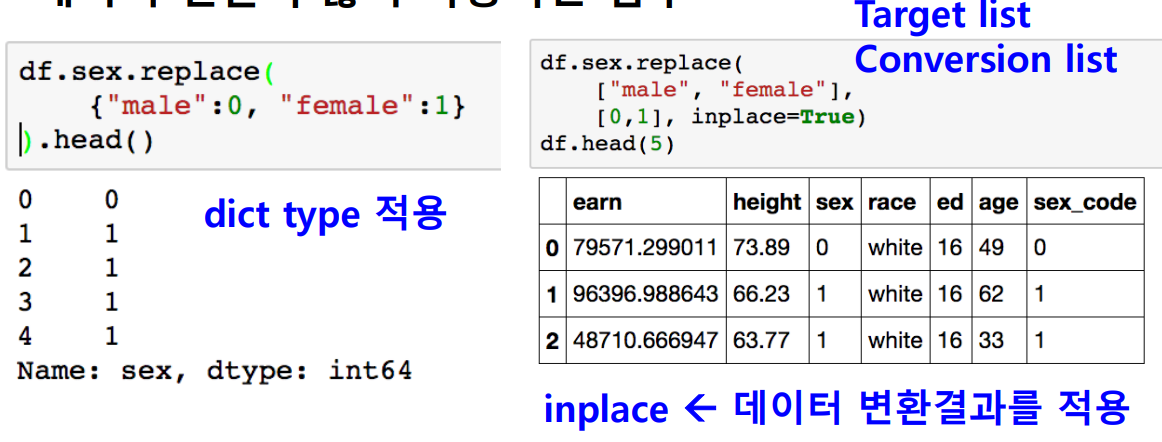
| map | - 딕셔너리 사용 - 단일 칼럼 변환 |
| apply | - dataframe과 series를 모두 다룰 수 있음 |
| applymap | - dataframe 전체 데이터 셀에 적용 |
apply (function)
- map과 달리, series 전체(column)에 해당 함수 적용
- 입력값을 series 데이터로 받아서 handling 가능

- 내장 연산함수를 사용할 때도 각 column 별로 결과값 반환 (mean, std)
- series 값도 반환 가능

applymap (function)
- series 단위가 아닌 element 단위로 함수 적용
- dataframe의 모든 element에 대해 원하는 함수 적용

Built-in function
df.describe()
- numeric type 데이터 요약 정보를 보여줌
df. .unique()
- series data의 유일한 값의 list를 반환함
df.sum(axis = 0) column 별 합
df.sum(axis =1) row 별 합
df.isnull()
- column 또는 row 값의 NaN (null) 값의 index를 반환
df.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
- column 값을 기준으로 데이터 sorting
- by : 정렬 기준이될 레이블입니다.
axis : {0 : index / 1: columns} 정렬할 레이블입니다. 0이면 행, 1이면 열을 기준으로 정렬합니다.
inplace : 원본을 대체할지 여부입니다. True일 경우 원본을 대체하게 됩니다.
kind : 알고리즘 모드 입니다. 모드는 총 4종으로 quicksort, mergesort, heapsort, stable이 있는데,
속도와 효율성의 차이를 갖습니다. 기본적으로 quicksort이며, 자세한건 numpy doc에서 확인 가능합니다.
na_position : {first / last} Na값의 위치입니다. 기본값은 last로 정렬시 맨 뒤에 위치합니다.
ignore_index : 인덱스의 무시 여부입니다. True일 경우 인덱스의 순서와 상관없이 0,1,2,... 로 정해집니다.
key : 이 인수를 통해 정렬방식으로 함수를 사용할 수 있습니다. lamba의 사용이 가능합니다.
'''
col1 col2 col3
row1 -3.0 A 17
row2 NaN D 31
row3 7.0 D -8
row4 15.0 Z 3
row5 0.0 NaN -7
'''
df.sort_values(by='col3')
'''
col1 col2 col3 #col3을 기준으로 오름차순 정렬된 것을 확인할 수 있습니다.
row3 7.0 D -8
row5 0.0 NaN -7
row4 15.0 Z 3
row1 -3.0 A 17
row2 NaN D 31
'''
Correlation & Covariance
- 상관계수와 공분산을 구하는 함수
- df.corr(method='pearson', min_periods=1)
method : {pearson / kendall / spearman} 적용할 상관계수 방식입니다.
min_periods : 유효한 결과를 얻기위한 최소 값의 수 입니다. (피어슨, 스피어먼만 사용가능) - df.cov(min_periods=None, ddof=1)
min_periods : 공분산을 구할 최소 요소의 갯수 입니다. 요소의 갯수가 모자르면 NaN을 반환합니다. - df.corrwith(other, axis=0, drop=False, method='pearson')
other : 동일한 이름의 행/열을 비교할 다른 객체입니다.
axis : {0 : index / 1 : columns} 비교할 축 입니다. 기본적으로 0으로 인덱스끼리 비교합니다.
drop : 동일한 이름의 행/열이 없을경우 NaN을 출력하는데, 이를 출력하지 않을지 여부입니다.
method : {pearson / kendall / spearman} 적용할 상관계수 방식입니다.
'전공공부 > 인공지능' 카테고리의 다른 글
| one hot encoding (0) | 2022.07.25 |
|---|---|
| 딥러닝 학습방법 이해하기: 신경망, softmax, 활성함수, back propagation (0) | 2022.07.25 |
| pandas : series, dataframe (0) | 2022.07.23 |
| [jupyter] shift+tab으로 자동완성 안될 때 (0) | 2022.07.23 |
| 경사하강법 기반 선형회귀 알고리즘, 확률적 경사하강법 (0) | 2022.07.23 |