머신러닝, 딥러닝에서 의미하는 Generative model이 무엇인지
이를 이해하기 위한 기본적인 통계 이론, 다양한 Generative model의 아이디어, 구조
<목차>
1. Learning a Generative Model
- explicit model
2. Basic Discrete Distributions
- 베르누이 분포, 카테고리 분포
3. Conditional Independence
- chain rule
4. Auto-regressive Model
- NADE
- Pixel RNN
Generative Model이란
Generative Model은 주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델이다.
한 예시로, 강아지 사진이 주어졌다고 가정했을 때, 다음과 같은 확률분포 p(x)를 학습하고자 한다
- Generation : 강아지처럼 생긴 sampling
- Densitiy Estimation : 이미지 x가 주어졌을 때 그 분포 p(x)를 확인하여 강아지인지, 아닌지 구분 (anomaly detection)
- Generative model은 분류 모델을 포함함
- 입력이 주어졌을 때 확률값을 얻을 수 있는 모델(explicit model)
- 단순히 generation 만 할 수 있는 모델 (implicit model)
- Unsupervised representation learning : 데이터가 공통적으로 가지고 있는 특징을 배운다 (feature learning)
Basic Discrete Distribution
- 베르누이 분포
동전 던지기처럼 0또는 1 두가지 경우의 수가 나오는 분포 / 이 확률을 표현하기 위한 수는 한개가 필요함- D = {head, tail}
P(x = head) = p / p(x = tail) = 1-p
x ~ Ber(p)
- D = {head, tail}
- 카테고리 분포
주사위 던지기처럼 n개의 경우의 수가 나오는 분포 / 이 확률을 표현하기 위한 수는 n-1개 , sum to one이기 때문에- D = {1, ... ,m}
P(Y = i) =
Y ~ Cat(p1, ..., pm)
- D = {1, ... ,m}
ex)

- (말도 안되는 가정이긴 하지만) n개의 픽셀이 모두 독립(fully independent)이라고 생각하면 가능한 states 는
- 이 분포를 표현하기 위해 필요한 parmeter의 수는 n개이다.
binary 이미지가 가질 수 있는 경우의 수는 여전히 2^n개로 동일하지만 확률분포를 표현하는 파라미터의 수는 엄청나게 줄어듦을 알 수 있다.
이러한 Independent assumption은 우리가 표현할 수 있는 표현력을 굉장히 줄여버린다.
이런 Independent assumption을 가지고 binary 이미지를 모델링한다면 각각의 픽셀이 독립적이기 때문에 의미있는 이미지를 얻어낼 수 없을 것이다.
그래서 우리는 그 중간 어딘가를 원한다. 원하는 것을 얻기 위해서는 Conditional independence를 활용한다.
출처
Conditional Independence
1. joint distribution을 chain rule을 통해 conditional distribution으로 표현. independent 여부와 상관없이 항상 만족.
아래와 같이 chain rule을 사용하면 fully dependent 모델과 param 수는 같다.
=> chain rule, Conditional independence를 잘 활용해보자
2. i+1번째 픽셀은 i 번째 픽셀에만 dependent하다고 가정하면(Markov assumption)

chain rule로 얻어지는 수식이 다음과 같이 간단하게 표현된다.

이 경우 필요한 parameter 개수는 2^n-1 개이다.
=> chain rule로 결합분포를 조건부 확률로 바꾼뒤 Markov assumption과 Conditional independence를 사용하여 파라미터 갯수를 조절할 수 있다는 것이다.
=> chain rule, Conditional independence를 잘 활용한 모델을 Auto-regressive Model 이라고 한다.
Auto-regressive Model
28 x 28 흑백 이미지를 가지고 있다고 가정했을 때 우리의 목표는 분포 를 학습하는 것이다.
How can we parameterize p(x)?
chain rule, Conditional independence 을 사용하여 Auto-regressive Model을 만들어보자.
- 이전 한개에만 dependent하지않고 이전 모든 데이터에 dependent해도 Auto-regressive Model이라고 부른다.
이전 한개만 고려 -> AR 1 model, n개 고려 -> AR n model
어떤 식으로 conditional independent를 주는 지에 따라 structure가 달라짐. Markov assumption을 주는 것이 chain rule이 joint distribution을 쪼개는 데 어떤 영향을 주는가
- 데이터 순서 (ordering) 에 따라 모델의 성능이 좌우된다.
Nade(Neural Autoregressive Density Estimator)
- i번째 픽셀을 첫번째부터 i-1 번째 픽셀에 dependent하게 함.
첫번째는 아무것도 dependent하지 않음. 두번째 픽셀은 첫번째 픽셀값을 입력으로 받는 nn를 만들어서 single scalar가 나온 후에 sigmoid 통과
- 모델 입장에서는 입력 차원이 매번 달라짐. weight가 계속 커짐.
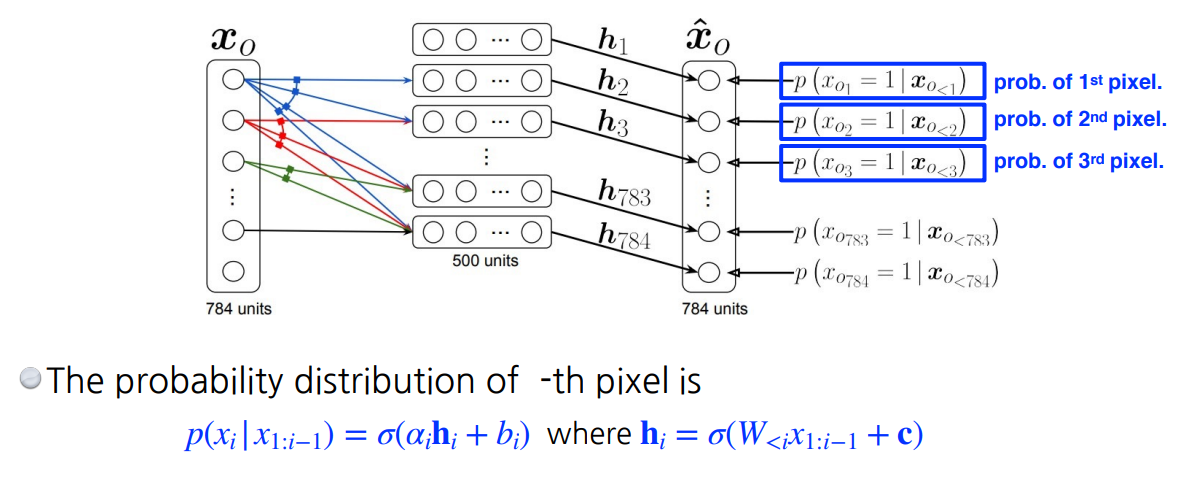
- NADE는 explicit model 로, 주어진 데이터에 대해 확률(density)을 계산할 수 있다
- 마지막 레이어에 가우시안 분포를 사용해서 continuous하게 만든다.

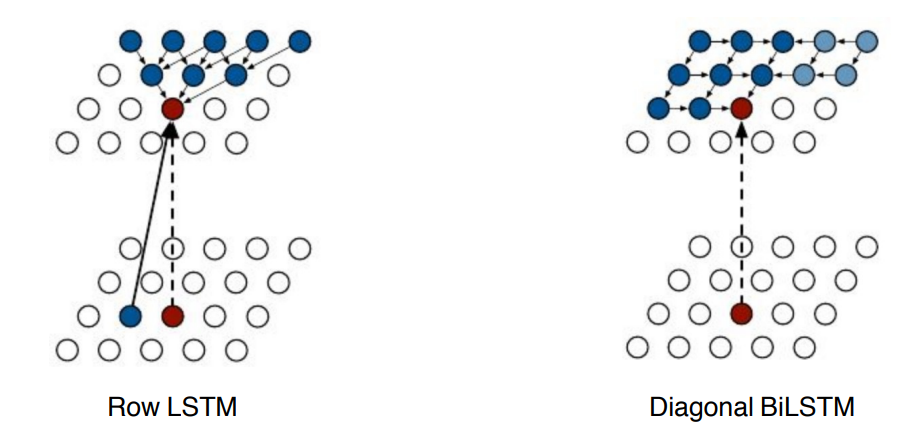
Pixel RNN

- use RNNs to define an auto-regressive mode
- NADE와의 차이: NADE는 fully connected layer(이전 값 전부 고려. dense layer)
- Pixel RNN은 ordering을 어떻게 하느냐에 따라서 Row LSTM, Diagonal BiLSTM으로 나뉨
<목차>
1. Latent Variable Models
2. Variational Auto-encoder
3. Generative Adversarial Network
- objective
4. DCGAN, Info-GAN, Text2Image, Puzzle_GAN, CycleGAN, Star-GAN, Progressive-GAN
Variational Auto-encoder
- Auto Encoder란 입력이 들어왔을 때, 해당 입력 데이터를 최대한 compression 시킨 후, compressed data를 다시 본래의 입력 형태로 복원 시키는 신경망임.(압축 과정이 encoding, 복원이 decoding) autoencoder는 generative model이 아니다.
- Variational Auto-encoder은 generative model이다. (엄밀한 의미에서 explicit model은 아니고 implicit한 모델임)
VAE가 AE와 다른 점
1. input x를 generate할 수 있는 확률 분포를 찾는 것이 목적임
2. latent vector z를 sampling함
3. 목적함수에 KL divergence를 활용한 regularization term이 포함됨
- generative model이 되기 위해서는 latent space에서 posterior distribution으로 z를 샘플링하고, 얘를 decoder에 태워서 나오는 이미지(값)을 generation result로 봄

- 목표: 관찰값이 주어졌을 때, 내가 관심있는 랜덤 변수의 분포인 사후확률(Posterior distribution)을 가장 잘 근사할 수 있는 분포를 구하는 것
- posterior distribution: observation이 주어졌을 때 관심 있는 것의 확률 분포 (일반적으로 계산 불가능할 때가 많음)
- variational distribution: posterior distribution 찾기가 어려워서 이를 근사하는 걸 찾는 데 이 근사하는 분포를 일컫음

뭔 지도 모르고 계산할 수 없는 PD와 optimize하려고 하는 VD의 거리를 줄이는 걸
ELBO를 maximize함으로써 구함
(우리가 Posterior distribution과 Variational distribution의 KL divergence를 줄이는 것이 목적인데, 이게 불가능 하므로 ELBO를 계산해서 키움으로서 반대급부로 내가 원하는 KL divergence의 값을 줄일 수 있는 것이다.)

ELBO를 나누어 보면 , Reconstruction term과 Prior Fitting Term으로 나뉜다.
목적: X를 잘 표현해내는 Latent space를 찾고 싶음

Reconstruction term은 encoder를 통해 x를 latent space로 보냈다가 다시 decorder를 통해 돌아올 때 reconstruction loss 를 줄이는 역할이고,
Prior Fitting Term은 x라는 이미지들을 latent space에 올렸을 때 이루는 분포가 Prior distribution과 같아지도록 하는 역할이다.
VAE의 한계
- explicit mocel이 아니다 : 입력이 주어졌을 때 likelihood를 계산하는 것이 어렵다(intractable model)
- Prior Fitting Term 가 미분가능해야 한다. : KL divergence를 사용하므로 대부분 모든 output dimension이 독립인 isotropic Gaussian 을 사용한다. 이때의 loss function은 다음과 같다.

- 하지만 prior dustribution으로 가우시안분포를 사용하지 않을 때는 AAE(Adversarial Auto Encoder) 를 사용한다.
GAN을 활용해서 latent distribution 사이의 분포를 맞춰주는 것, 이는 VAE의 prior fitting term 을 GAN objective func으로 바꿔주는 것이다. 이렇게 하면 샘플링만 가능하면 어떤 것이든 latent 분포로 사용할 수 있다.

Generative Adversarial Network
- 생성자(generator, G)와 구분자(discirimiator, D), 두 네트워크를 적대적(adversarial)으로 학습시키는 비지도 학습 기반 생성모델(unsupervised generative model)
- discriminator 성능이 좋아짐에 따라 generator 성능도 좋아짐. inclusive model
- G는 입력 z를 받아 실제 데이터와 유사한 데이터를 만들어내도록 학습되고, D는 G가 생성한 가짜 데이터를 구별하도록 학습됨. 이렇게 적대적으로 학습하여 실제 데이터의 분포에 가까운 데이터를 생성하는 것이 GAN의 목표

- VAE는 encoder(q)와 decoder(p)로 구성되며 encoder는 관측된 데이터 x를 받아서 잠재변수 z를 만들어내고, decoder는 encoder가 만든 z를 활용해 x를 복원해내는 역할을 한다. (x-> z-> x)
- 학습을 이렇게 하고 generation 단계에서는 latent distribution의 z는 샘플링해서 decoder을 태워서 나오는 x가 결과임.
- GAN은 Generator(G) 와 Discriminator(D)로 구성되며 G는 Zero-Mean Gaussian으로 생성된 z를 받아서 가짜 데이터를 만들고, D는 진짜와 가짜를 구분하도록 학습된다. GAN의 가장큰 장점은 두 네트워크가 적대적으로 학습하며 성능이 점점 좋아진다는 것이다.
GAN objective
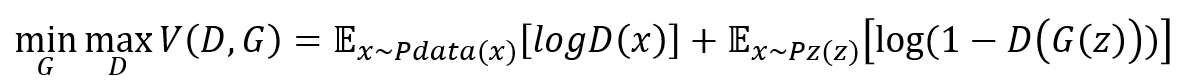
- generator과 discriminator 사이의 minimax game
- G는 목적함수를 작게만드는 방향으로 학습하고, D는 목적함수를 크게만드는 방향으로 학습하며 균형점을 찾아가는 방식

실제 데이터(x)를 입력하면 높은 확률이 나오도록 하고(D(x)를 높임)
가짜 데이터(G(z))를 입력하면 확률이 낮아지도록(1−D(G(z))를 낮춤=D(G(z))를 높임) 학습된다.
다시 말해 D는 실제 데이터와 G가 만든 가상데이터를 잘 구분하도록 조금씩 업데이트된다.

Zero-Mean Gaussian으로 뽑은 노이즈 z를 받아 생성된 가짜 데이터(G(z))를 D에 넣었을 때, 실제 데이터처럼 확률이 높게 나오도록(1−D(G(z))를 높임=D(G(z))를 낮춤) 학습된다.
다시 말해 G는 D가 잘 구분하지 못하는 데이터를 생성하도록 조금씩 업데이트된다.
GAN 변형 모델들
- DCGAN

초기 GAN은 MLP(dense layer). 이걸 이미지 domain으로 한 게 DCGAN.
Deep Convolutional GAN(DCGAN)은 GAN을 개선한 모델. GAN은 학습이 어렵다는 점이 최대 단점인데, DCGAN은 대부분의 상황에서 안정적으로 학습이 되는 아키텍처이다.
- Info-GAN
z를 통해서 단순히 이미지만 만드는 게 아니라 class라는 c를 random하게 집어넣음. generation할 때 GAN이 특정 모드에 집중할 수 있게 (one hot vector, conditional vector에 집중하게). 마치 multi model distribution 학습하는 걸 c를 통해 잡아줌

- Text2Image
문장을 집어넣으면 Conditional GAN을 활용해 이미지를 출력함
- Puzzle-GAN
이미지 안의 sub patch가 들어가면 얘를 통해 원래 이미지 복원
- CycleGan **** cycle-consistency loss 중요****
이미지 사이 domain을 바꿈
장점: 똑같은 사진일 필요 없음. 알아서 바꿈.


- Star- GAN
이미지를 control할 수 있게 함
- Progressive GAN
고차원의 이미지를 잘 만들 수 있음


'AI TECH' 카테고리의 다른 글
| [실습] 전처리 Corpus cleaning (0) | 2022.10.10 |
|---|---|
| NLP: Bag of Words, NaiveBayes Classifier (0) | 2022.10.10 |
| Sequential Models - Transformer (0) | 2022.10.06 |
| Sequential Models - RNN/LSTM/GRU (0) | 2022.10.06 |
| Computer Vision: segmentation, detection (0) | 2022.10.06 |