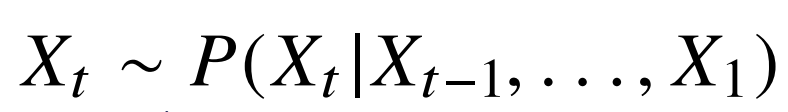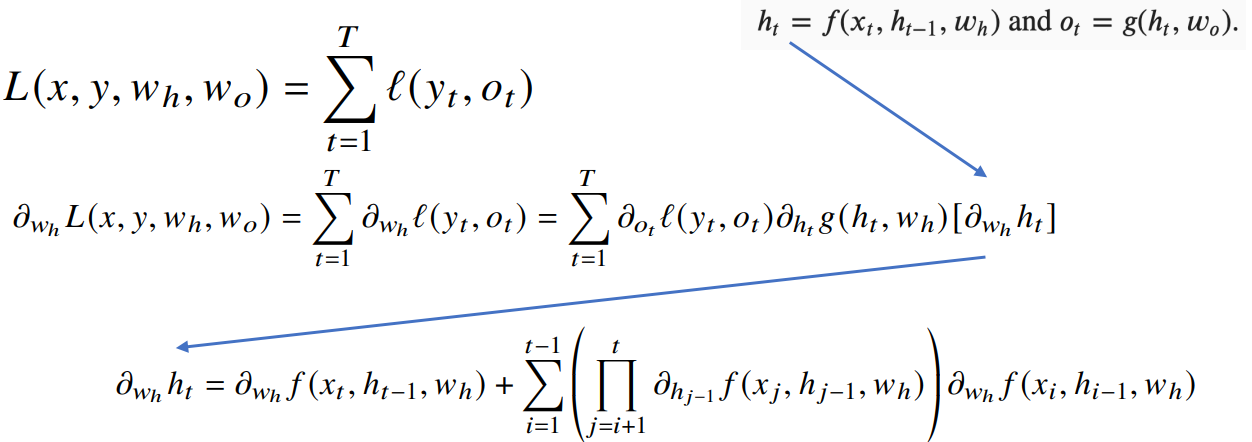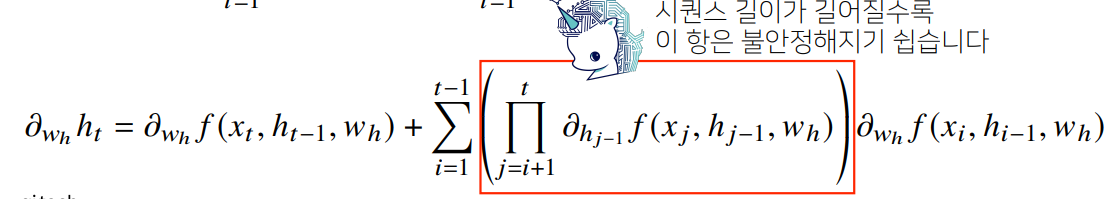2. Sequential model의 정의와 종류 - Naive sequence model - Autoregressive model (자기회귀모델) - Markov model (first-order autoregressive model) - Latent autoregressive model
3. RNN 이해하기 - 기본 구조 - BPTT
4. 딥러닝에서 sequential data를 다루는 Recurrent Neural Networks 에 대한 정의와 종류 - (Vanila) RNN : Short term - LSTM : long term - Gated Recurrent Unit : parameter을 줄이자
Sequence 데이터 다루기
IID 독립동등분포로 들어오는 data와 달리 sequence 데이터(시계열(time-series)데이터)는 독립적으로 들어오지 않는 경우가 많음
어떻게 학습하는 지를 알아보자!
이전 시퀀스의 정보를 가지고 앞으로 발생할 데이터의 확률분포를 다루기 위해 조건부확률을 이용할 수 있음
베이즈 정리 사용
아래의 조건부확률을 모델링하는 게 시퀀스 데이터를 다루는 첫 step
하지만 위 조건부확률은 과거의 모든 정보를 사용하지만 시퀀스 데이터를 분석할 때 모든 과거 정보들이 필요한 것은 아님
길이가 가변적인 데이터를 다룰 수 있는 모델이 필요함 (위 식에서 Xt-1, .. , X1 부분. 즉, 조건부에 들어가는 데이터 길이는 가변적임)
Sequential Model
- sequential data는 input의 길이를 모름 -> fully connected layer, CNN을 사용할 수 없음
Autogressive Model
Naive sequence model
Autoregressive model
ex.language model 고려해야하는 정보량이 늘어남
과거의 몇 개만 보기로 고정
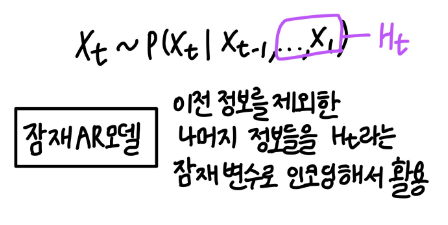
자기회귀모델 vs 잠재 AR 모델
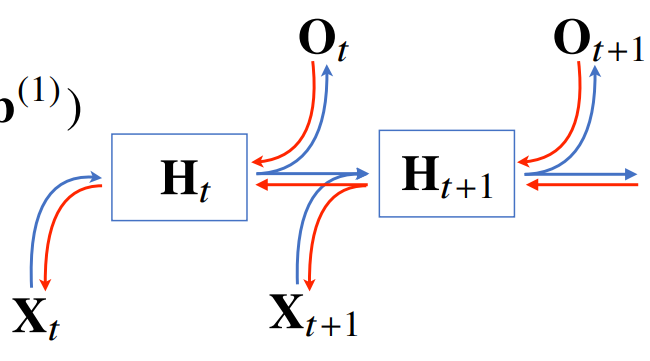
- 자기회귀모델에서 타우를 결정하는 데도 사전 지식이 필요할 때가 있음 - 잠재 AR 모델은 가변적인 데이터를 고정된 길이로 바꿀 수 있다는 장점이 있음 - 잠재 AR 모델에서 과거의 정보를 잠재변수로 어떻게 인코딩할 것인가? -> RNN 사용 - RNN은 잠재변수 Ht를 신경망을 통해 반복해서 사용해, 시퀀스 데이터의 패턴을 학습하는 모델임
Markov model (first-order autoregressive model)
Markov property : n+1 회에서의 상태는 오직 n회에서의 상태, 혹은 그 이전 일정 기간의 상태에만 영향을 받는 것을 의미. 예를 들면 동전 던지기는 독립 시행이기 때문에 n번째의 상태가 앞이든지 뒤이든지 간에 n+1번째 상태에 영향을 주지 않는다. 하지만 1차 Markov Chain은 n번째 상태가 n+1번째 상태를 결정하는데 영향을 미친다.
Markov model : 어떤 상태로 들어갈 확률이 들어가기 직전 상태에만 의존하는 확률과정. 즉, 다음에 나올 상태에 대한 확률값이 직전 과거에만 종속된 모델. 어제의 일이 오늘에만 영향을 미치는 것
(장점) joint distribution 표현하기 쉬워짐 (단점) 많은 정보를 버릴 수 밖에 없음
Latent autoregressive model
- Hidden state가 과거의 정보를 요약
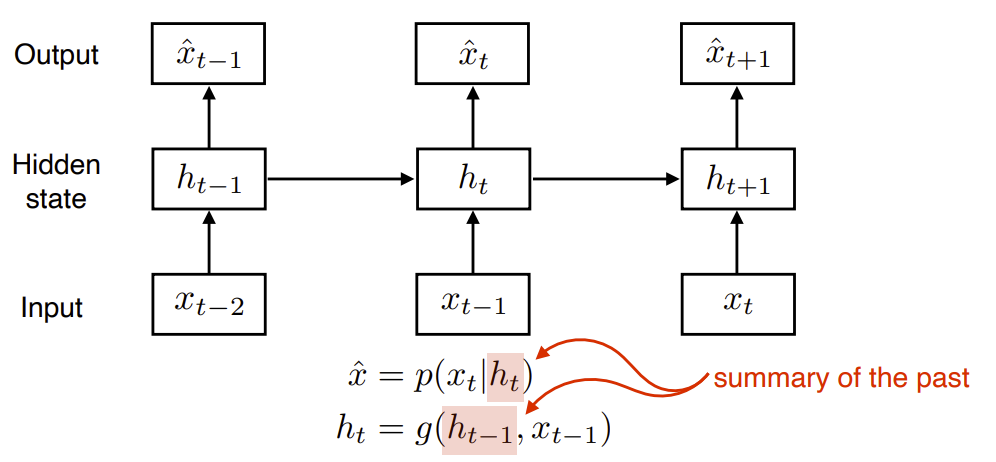
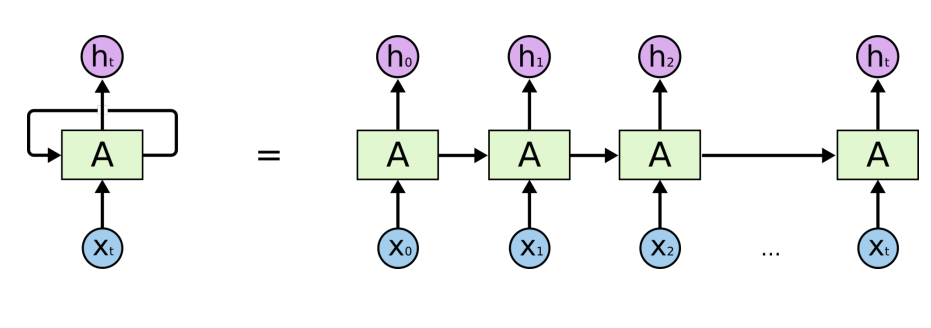
RNN 이해하기
RNN의 기본 모형은 MLP와 유사
잠재변수와 입력 데이터만 sequence에 따라 변함
RNN은 이전 순서의 잠재변수와 현재의 입력을 활용해 모델링
RNN의 역전파는 잠재변수의 연결그래프에 따라 순차적으로 계산함
=> RNN의 역전파 방법: Backpropagation Through Time(BPTT)
BPTT
BPTT를 통해 RNN의 가중치행렬의 미분을 계산하면
아래와 같이 미분의 곱으로 이루어진 항이 계산됨
마지막 줄에서
현재 시간부터 예측이 끝나는 t시점까지 sequence 길이가 길어지는 경우
BPTT를 통한 역전파 알고리즘의 계산이 불안정해지므로
길이를 끊는 것이 필요함
=> 이를 truncated BPTT라고 부름
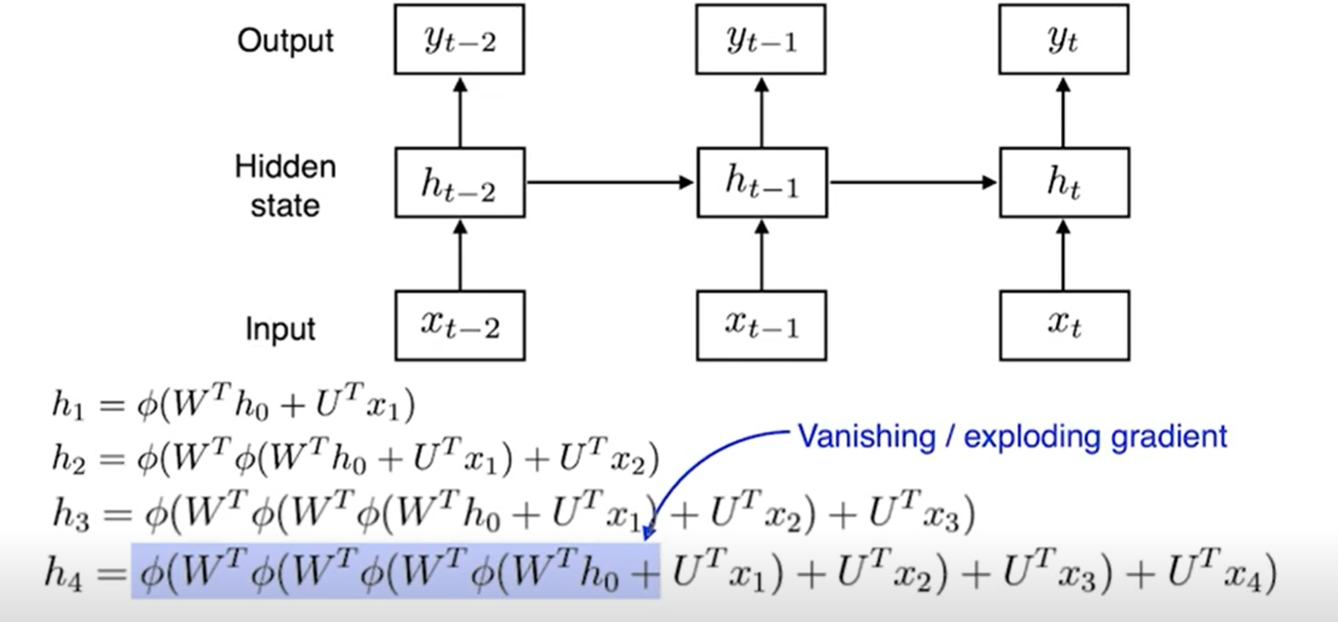
기울기 소실 vanishing 문제를 해결하기 위해
Vanilla RNN은 길이가 긴 시퀀스를 처리하는데 문제가 있음. 이를 해결하기 위해 등장한 RNN 네트워크가 LSTM과 GRU임
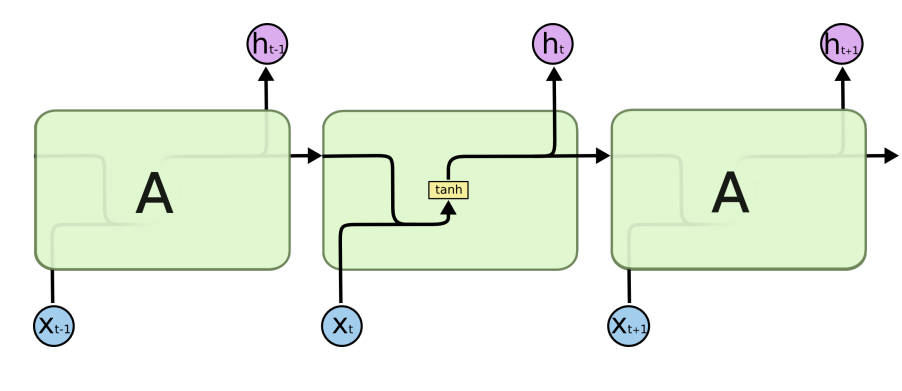
Recurrent Neural Networks (Vanila RNN)
자기 자신으로 돌아오는 게 있음
RNN 구조를 시간 순으로 보면 입력이 굉장히 많은 fully connected layer로 풀 수 있음
short-term dependencies: 아주 과거의 정보는 고려하기 힘듦
RNN 학습이 왜 어려운가?
중첩된 구조
activation func가 sigmoid인 경우 vanishing gradient descent
ReLU인 경우 exploiting
<RNN의 문제점> 1. 순차적 모델링 방식이기 때문에 Data 2를 살펴볼 때 Data1 및 Data3가 동시에 고려될 수 없다 2. 지역 정보만 활용하기 때문에 Data3를 모델링할 때 원거리에 있는 정보가 원활하게 활용되기 힘들다.
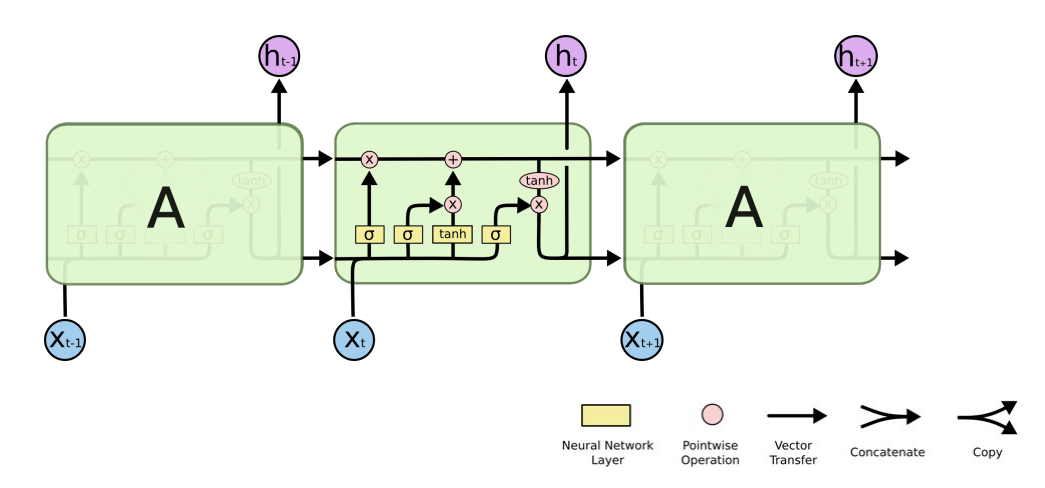
Long Short Term Memory
(좌) RNN / (우) LSTM
LSTM이 왜 Long term dependency를 잡는 게 유용한가?
들어오는 거 세 개. 나가는 거 하나
previous hidden state = 지난 output
이전 cell state를 얼마나 지워버릴 지 정하고, 어떤 값을 올릴 지 C tilda를 정하고, update된 cell state와 candidate를 조합해서 새로운 cell state를 만들고, 그 정보를 얼만큼 빼낼지 정한다
c tilda는 cell state candidate
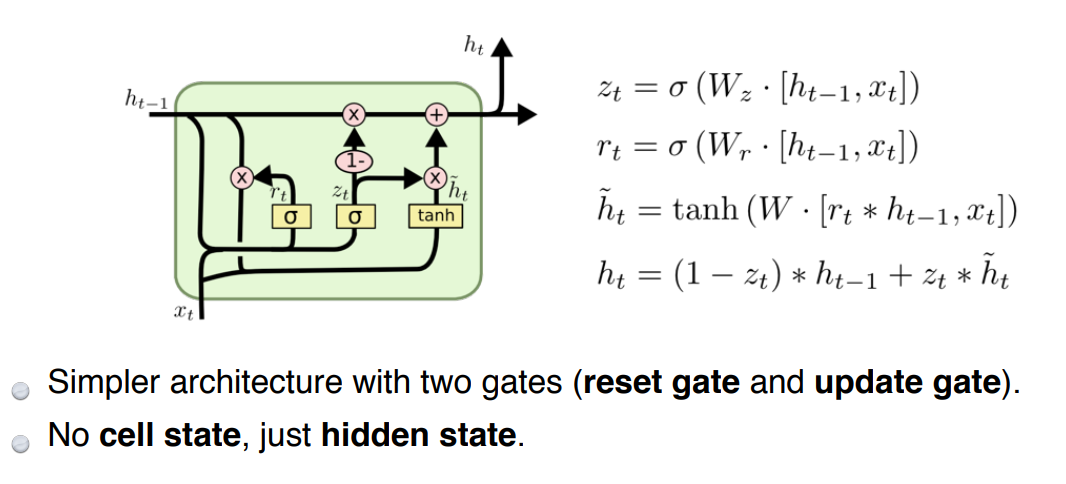
Gated Recurrent Unit
hidden state가 output이고 다음번에 들어감
LSTM을 쓸 때보다 GRU 쓸 때 더 잘됨(둘 다 요새는 잘 안 쓰임)
- 결과는 같은데 parameter을 더 쓰니까 generalization 잘됨
Further Question
Q. LSTM에서는 Modern CNN 내용에서 배웠던 중요한 개념이 적용되어 있습니다. 무엇일까요?
A. Skip-Connection of ResNet
Concatenation of DenseNet
Q. Pytorch LSTM 클래스에서 3dim 데이터(batch_size, sequence length, num feature), `batch_first` 관련 argument는 중요한 역할을 합니다. `batch_first=True`인 경우는 어떻게 작동이 하게되는걸까요?
A. If your input data is of shape (seq_len, batch_size, features)
then you don’t need batch_first=True and your LSTM will give output of shape (seq_len, batch_size, hidden_size).
If your input data is of shape (batch_size, seq_len, features)
then you need batch_first=True and your LSTM will give output of shape (batch_size, seq_len, hidden_size).
Q. RNN, LSTM, GRU 는 각각 어떤 문제를 해결할 때 강점을 가질까요?
A. RNN은 short term memory가 중요한 문제에서 강점을 가진다.
LSTM은 long term dependency를 가지고 있어서 오래된 데이터를 고려해야할 때 강점을 가진다.
GRU는 LSTM보다 parameter 수가 적어서 generalization이 중요한 문제에 강점을 가진다.