<목차>
1. pivot table
- crosstab
2. merge
3. join
- inner join
- full(outer) join
- left join
- right join
4. concat
5. DB persistence
- XLS persistence
- pickle persistence
pivot table
- Index 축은 groupby와 동일
- Column에 추가로 labeling값을 추가하여 Value에 numeric type값을 aggregation 하는 형태
df_phone.head()
crosstab
- 두 칼럼에 교차 빈도, 비율, 덧셈 등을 구할 때 사용
- Pivot table의 특수한 형태
- User-Item Rating Matrix 등을 만들 때 사용 가능
#pivot table이었다면
df_movie.pivot_table(['rating'], index = df_movie.critic, columns = df_movie.title,
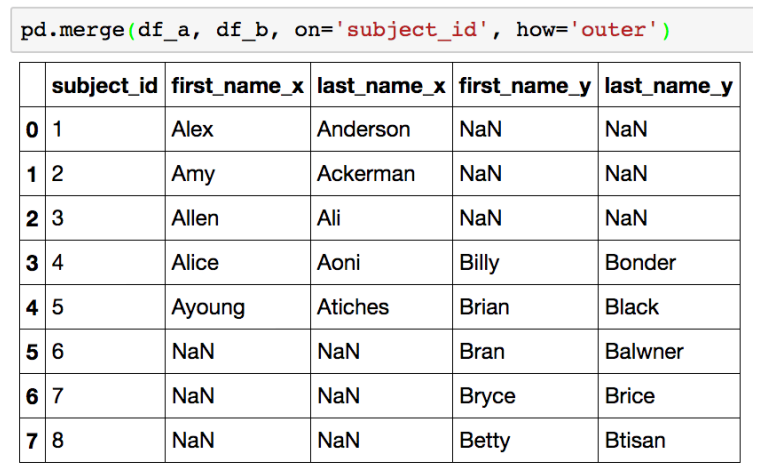
aggfunc = "sum", fill_value = 0)merge pd.merge(df_a, df_b, on = ' ' , how = ' ')
- SQL에서 많이 사용하는 Merge와 같은 기능
- 두개의 데이터를 하나로 합침
raw_data = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_score': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
df_a = pd.DataFrame(raw_data, columns = ['subject_id', 'test_score'])
raw_data = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
df_b = pd.DataFrame(raw_data, columns = ['subject_id', 'first_name', 'last_name'])
pd.merge(df_a, df_b, on='subject_id')
#subject_id를 기준으로 merge
pd.merge(df_a, df_b, left_on = 'subject_id', right_on 'subject_id')
#두 dataframe의 column 이름이 다를 때


- join method





concat
- 같은 형태의 데이터를 붙이는 연산작업


df_new = pd.concat([df_a, df_b])
df_new.reset_index()
df_a.append(df_b)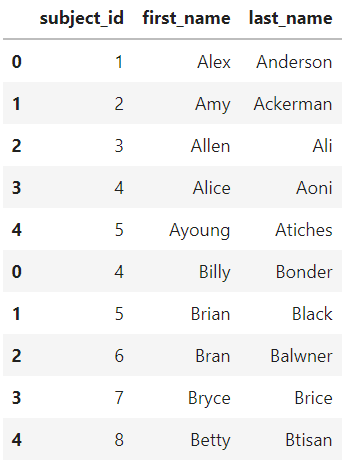
df_new = pd.concat([df_a, df_b], axis=1)
df_new.reset_index()
DB persistence
- data loading시 db connection 기능을 제공
#Database 연결 코드
import sqlite3
conn = sqlite3.connect("./data/flights.db")
cr = conn.cursor()
cur.execute("select *from airlines limit 5;")
results = cur.fetchall()
results
#DB 연결 conn을 사용하여 dataframe 생성
df_airlines = pd.read_sql_query("select *from airlines;", conn)XLS persistence
- Dataframe의 엑셀 추출 코드
- Xls 엔진으로 openpyxls 또는 XlsxWrite 사용
- conda install openpyxl
- conda install XlsxWriter
writer = pd.ExcelWriter('./data/df_routes.xlsx', engine='xlsxwriter')
df_routes.to_excel(writer, sheet_name='Sheet1')Pickle persistence
가장 일반적인 python 파일 persistence
df_routes.to_pickle("./data/df_routes.pickle")'전공공부 > 인공지능' 카테고리의 다른 글
| 통계학 맛보기(뒷부분 어려움) (0) | 2022.07.26 |
|---|---|
| 확률론 맛보기: 확률분포, 이산/연속형 확률변수, 기대값, 몬테카를로 샘플링 (0) | 2022.07.25 |
| Pandas 3편 : Groupby (0) | 2022.07.25 |
| one hot encoding (0) | 2022.07.25 |
| 딥러닝 학습방법 이해하기: 신경망, softmax, 활성함수, back propagation (0) | 2022.07.25 |