<목차> 1. GPT-2 2. GPT-3 3. ALBERT - Factorized Embedding Parameterization, Cross-layer Parameter Sharing, Sentence Order Prediction 4. ELECTRA 5. Light-weight Models 6. Fusing Knowledge Graph into Language Model
<요약> GPT-1과 BERT 이후 등장한 다양한 self-supervised pre-training 모델들에 대해 알아봅니다. GPT-1과 BERT 이후 pre-training task, 학습 데이터, self-attention, parameter 수 등에 있어서 여러가지 개선된 모델들이 등장했습니다. GPT 시리즈가 2와 3로 이어지면서 일부 데이터셋/task에 대해서는 사람보다 더 뛰어난 작문 능력을 보여주기도 합니다. 이로 인해, model size 만능론이 등장하며 resource가 부족한 많은 연구자들을 슬프게 만들기도 했습니다.
다른 연구 방향으로 transformer의 parameter를 조금 더 효율적으로 활용하고 더 나은 architecture/pre-training task를 찾고자 하는 ALBERT와 ELECTRA에 대해서 알아봅니다. 두 모델 모두 풍부한 실험과 명확한 motivation으로 많은 연구자들의 관심을 받은 논문입니다. 위에서 설명드린 연구방향과는 또 다른 연구 흐름으로 경량화 모델/사전 학습 언어 모델을 보완하기 위한 지식 그래프 integration에 대해 소개한 논문들을 간략하게나마 알아봅니다
- Big transformer Language Model: 모델 구조는 GPT-1과 크게 다를 바 없다. 지금까지 주어진 단어를 바탕으로 다음 단어를 예측하는 방식으로 학습을 진행한다.
- GPT-1과의 차이점은 Training data를 많이 증가 시켰고, 데이터셋은 잘 쓰여진 글을 활용해서 학습을 시켰다는 점이다. 데이터셋에는 Reddit이라는 포털 사이트에서 up-vote가 최소 3 이상인 외부 링크도 스크랩을 하는 방식이 추가되었다.
데이터를 전처리(prepocess)할 때는 Byte pair encoding(BPE)를 사용해서 sub word level에서 word embedding을 도출해냈다.
- GPT-2는 Language model이 zero-shot setting으로 down-stream task를 다룰 수 있다는 잠재적인 능력을 보여줬다.
zero-shot 은 “모델이 학습 과정에서 배우지 않은 작업을 수행하는 것”을 의미한다. zero-shot learning은 특정 문제에 대해 학습한 경험이 없어도 이미 저장된 데이터를 변형하고 해석하여 학습했던 문제와 학습하지 않았던 문제 간의 특징을 분석해 답을 예측한다.
down-stream task는 구체적으로 풀고 싶은 문제들을 말한다. 자연어 처리 분야에서는 언어모델을 pre-train방식을 이용해 학습을 진행하고, 그 후에 원하고자 하는 태스크를 fine-tuning 방식을 통해 모델을 업데이트 하는 방식을 사용하는데 이때의 task를 down-stream task라고 한다.
- 참고로 GPT-2의 아이디어는 The Natural Language Decathlon: Multitask Learning as Question Answering이라는 논문으로부터 나왔다. 논문의 내용은 자연어 처리의 대부분의 문제가 QA로 해결된다는 것이다.
- Model
모델은 Layer가 위로 올라감에 따라 index에 따라 init 값을 더 작게 해줬다. 그 이유는 Layer가 올라 갈수록 선형 변환의 값이 0에 가까워지도록 해서, 위쪽의 Layer의 영향력이 작아지도록 구성했다.
- 모델의 Task 수행도
1. 이렇게 구성된 모델을 가지고 Conversation Question Answering(CoQA)을 수행해보자. Fine-tuning을 하지 않았을 때(zero-setting)에도 F1-score가 대략 55에 도달하는 것을 확인할 수 있다. 일반적으로는 Fine-tuning의 과정을 거쳐야 하고 이때의 F1-score은 89이다.
2. 문단 요약(CNN과 Daily mail Dataset) Task를 수행할 때에는 TL;DR (Too long, didn't read)라는 토큰을 활용해서 짧게 요약하는 Task임을 알려줬다.
3. 번역 Task의 경우에는 문장을 주고 in French 와 같은 내용을 적어줘서 해당 언어로 번역할 수 있도록 했다.
GPT-3
- GPT-2의 모델 구조를 변경하는 것이 아닌, 모델 사이즈를 엄청 크게 늘리는 방식으로 개선했다. 많은 데이터와 3.2M라는 큰 batch size를 통해 학습을 진행했다.
- GPT-3에서는 GPT-2에서 사용했던 zero-shot setting의 가능성을 놀라운 수준으로 끌어올렸다.
GPT-3에서는 One-shot(학습데이터 1개), Few-shot(학습데이터 여러 개)의 방법을 적용해서 실험했는데, 모델 자체는 변형하지 않고(fine-tuning 없이) 인퍼런스 할 때에만 예시를 제시해주는 방식을 적용했다. one-shot setting이 zero-shot 보다 좋은 성능을 보이는 것을 확인할 수 있다.
게다가 모델 사이즈를 증가시키면 zero-shot 성능이 계속해서 좋아지는 것을 확인할 수 있다.
<zero-shot, one-shot, few-shot 비교>
zero-shot
Predict the answer given only a natural language description of the task
one-shot
See a single example of the task in addition to the task description
- 기존의 BERT 모델이 가지고 있던 Memory Limitation과 Training 속도에 대한 문제점을 해결하면서도, 성능의 큰 하락이 없도록 유지했다. 해결책은 바로 Factorized Embedding Parameterization, Cross-layer Parameter Sharing, Sentence Order Prediction 이다.
- Factorized Embedding Parameterization
입력 벡터의 차원을 줄여서 압축하고, 이러한 방법을 통해서 연산량과 모델 사이즈를 줄이는 방법으로, 큰 모델의 BERT 모델을 경량화하는 주된 아이디어이다.
4차원으로 embedding 되는 벡터를 2차원으로 줄이는 예시를 살펴보자. ALBERT에는 선형 변환을 위한 matrix W가 있다.
위와 같이 좌측의 parameter(50000개)가 우측의 parameter(9000개)로 줄어듦을 확인할 수 있다.
- Cross-layer Parameter Sharing
적층해서 쌓는 self-attention block 에 존재하는 선형 변환 matrix들이 같은 파라미터들을 공유하는 방법이다.
즉, 서로 다른 self-attention 내부의 key, value, query로 만드는 weight와 마지막에서 모든 head에서 나온 벡터를 concat 후에 곱해지는 weight를 공유한다.
원래는 self-attention은 각기 다른 파라미터를 가지고 있지만, 이것들을 공유함으로써 파라미터를 줄이고자 노력했다.
ALBERT에서는 여러 가지 실험을 했다.
Shared-FFN
Only sharing feed-forward network parameters across layers
Shared-attention
Only sharing attention parameters across layers
All-Shared
Both of them
Shared-FFN은 Feed-forward network parameters만 공유하는 방법(concat 후 곱해지는 weight)이며,
Shared-attention은 self-attention의 파라미터들을 공유하는 방법이고,
All-Shared는 둘 다 공유하는 방법이다.
이렇게 했을 때, 성능은 파라미터가 많은 shared-attention, shared-FFN, all-shared 방법 순으로 좋았다.
- Sentence Order Prediction
기존의 BERT에서 사용되던 pretraining 기법은 Masked LM, Next Sentence Prediction 두 가지였다. 하지만 이전에 존재했던 Next Sentence Prediction은 ALBERT에서는 너무 쉬운 Task 였다.
BERT의 Next sentence prediction이란? Next Sentence Prediction은 두 문장을 주고, 두 문장이 같은 document에서 연달아 나온 문장인지, 혹은 다른 document에서 랜덤하게 뽑은 문장인지를 예측하도록 하는 방식이다.
그래서 ALBERT에서는 연속하는 문장을 입력으로 넣거나 연속하는 문장을 순서를 뒤집어서 넣는 것을 맞추는 방식을 제안했다.
Sentence Order Prediction은 Next Sentence Prediction보다 맞추기 어렵고 논리적인 관계 속에서 이해해야 맞출 수 있게 된다.
이렇게 학습하게 되면 SQuAD1.1과 SQuAD2.0에서 특히 성능이 좋아지는 것을 확인할 수 있다.
그리고 ALBERT도 더 많은 파라미터를 가지는 ALBERT 모델로 학습을 하면 기존의 모델보다 더 좋은 성능을 가지게 된다.
- ELECTRA는 Generator(BERT와 흡사)와 Discriminator(ELECTRA)를 사용하는 강화학습 아이디어로 학습하는 방식을 사용했다. Discriminator은 self attention을 쭉 쌓은 형태이다.
- MLM(Masked Language Model) 모델인 Generator는 [mask]된 단어를 복원하는 역할을 하고, 이렇게 만들어진 문장을 Discriminator에 넣어서 해당 단어가 원래 있던 단어인지 아닌지를 확인하는 역할을 수행한다(단어 별로 예측해서 답과 비교 "이진 분류").
- Generator, Discriminator은 적대적 관계(Adversarial Learning)로 학습이 진행된다.
ex) GAN 아이디어를 착안해서 Pretrained model을 제안
- 최종적으로 모델 학습을 진행한 뒤에는 pre-trained 모델로 Discriminator를 활용한다.
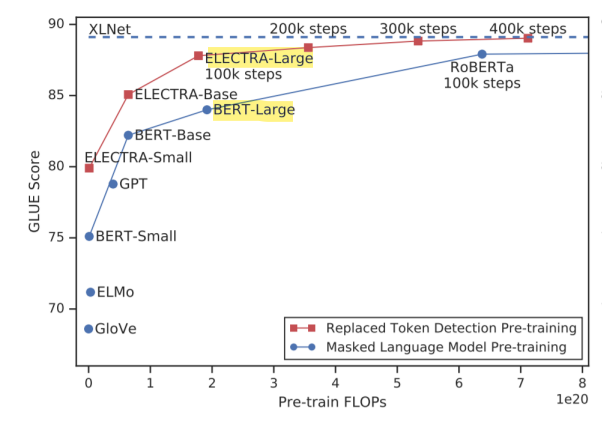
- ELECTRA는 같은 사이즈의 BERT 모델보다 좋은 성능을 가진다.
Light-weight Models
GPT-3처럼 대용량의 데이터, 좋은 성능의 GPU가 필요로 하지만 그만큼 인프라가 갖춰져 있지 않은 곳에서는 사실 활용하기가 어렵다. 그래서 경량화 방향으로도 연구가 되고 있습니다. Light-weight Model들은 큰 사이즈 모델들의 성능을 최대한 유지하면서 계산속도를 빠르게 하는 것에 집중하고 있다. Light-weight Model은 소형 device에서도 활용할 수 있다.
Transformer의 구현체를 라이브러리 형태로 만드는 회사인 hugging face가 제작했다.
기본적인 아이디어로, Teacher model과 Student model이 존재하는 데 Teacher model이 학습하는 것을 Student model이 잘 따라갈 수 있도록 만들었다.
Teacher가 "I"가 입력으로 들어왔을 때, 다음 단어로 "go"라고 예측하면, Student model은 Teacher가 가지고 있는 분포를 활용해서 정답을 내는 방식으로 진행된다.
TinyBERT
Knowledge distillation을 활용해서 BERT를 경량화한 모델이다.
DistillBERT에서 teacher의 분포를 사용하는 것뿐만 아니라, 중간 결과물들도 배우는 모델이 TinyBERT이다. 그래서 Teacher에서 나온 값과 최대한 비슷하게 하도록 MSE loss를 통해서 학습이 진행됩니다. 하지만, student 모델의 경우 차원수가 teacher 다를 수 있기 때문에 teacher 벡터를 Fully connected layer를 추가해서 동일한 벡터를 만들어준다.
Knowledge distillation이란?
Knowledge distillation은 미리 잘 학습된 큰 네트워크의 지식을 실제로 사용하고자 하는 작은 네트워크에 전달하는 방식을 의미한다.
Fusing Knowledge Graph into Language Model
최신 연구흐름은 Knowledge graph(외부 정보)를 잘 결합하는 방향으로 진행되고 있다.
예를 들면, BERT는 해당 주어진 문단에서 필요한 단어가 없는 경우에는 그것을 잘 찾지 못한다는 어려움이 있다.
따라서 이를 해결하는 방향의 연구가 발전하고 있다.
개체(땅)와 개체(파다)를 연결해서 관계를 정형화하는 것이 Knowledge Graph이다.