
pandas : series, dataframe
https://github.com/TEAMLAB-Lecture/AI-python-connect/tree/master/codes/ch_2/3
GitHub - TEAMLAB-Lecture/AI-python-connect
Contribute to TEAMLAB-Lecture/AI-python-connect development by creating an account on GitHub.
github.com
<목차>
1. Series
- Dataframe의 column을 표현
2. DataFrame
- loc, iloc
3. Selection & Drop
4. Dataframe operation
- Series operation
- Series + Dataframe
pandas
- panel data, 파이썬의 데이터 처리의 사실상의 표준인 라이브러리
- 파이썬에서 일종의 엑셀과 같은 역할을 하여 데이터를 전처리하거나 통계 처리시 많이 활용하는 피봇 테이블 등의 기능 사용 가능
- numpy를 기반으로 하여 개발되어 있음
데이터 로딩 pd.read_csv( ) .head()
import pandas as pd #라이브러리 호출
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data' #Data URL
# data_url = './housing.data' #Data URL
df_data = pd.read_csv(data_url, sep='\s+', header = None) #기존 데이터를 불러와서 dataframe 생성
#csv 타입 데이터 로드, separate는 빈공간으로 지정하고, Column은 없음
df_data.head() #처음 다섯줄 출력
df_data.columns = [
'CRIM','ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO' ,'B', 'LSTAT', 'MEDV']
# Column Header 이름 지정
df_data.head()
type(df_data.values) # 출력값: numpy.ndarray1. Series : column vector을 표현하는 object
- 아무 type의 data 가능, index label은 order될 필요 없음, 중복 값 가능
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
list_data = [1,2,3,4,5]
example_obj = Series(data = list_data)
example_objlist_data = [1,2,3,4,5]
list_name = ["a","b","c","d","e"]
example_obj = Series(data = list_data, index=list_name) #index 이름 지정
example_obj
'''
a 1
b 2
c 3
d 4
e 5
dtype: int64
'''
example_obj.index #index list만
#Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
example_obj.values #값 list만
#array([1, 2, 3, 4, 5])
dict_data = {"a":1, "b":2, "c":3, "d":4, "e":5}
example_obj = Series(dict_data, dtype=np.float32, name="example_data")
#data type 설정, series 이름 설정
example_obj
'''
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
'''
example_obj["a"] #1.0 data index에 접근, 값 할당도 마찬가지
exaple_obj.name = "alphabet" #data에 대한 정보 저장 가능
example_obj
'''
alphabet
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
'''
index 값을 기준으로 series 생성
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
dict_data_1 = {"a":1, "b":2, "c":3, "d":4, "e":6}
indexes = ["a","b","c","d","e","f","g","h"]
series_obj_1 = Series(dict_data_1, index=indexes)
series_obj_12. DataFrame: series를 모아서 만든 data table
- 기본 2차원
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
pop = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
DataFrame(pop)
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
# Example from - https://chrisalbon.com/python/pandas_map_values_to_values.html
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'city': ['San Francisco', 'Baltimore', 'Miami', 'Douglas', 'Boston']}
df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'city'])
df
DataFrame(raw_data, columns = ["age", "city"])
Column 선택해서 series 추출
df = DataFrame(raw_data, columns = ["first_name","last_name","age", "city", "debt"])
df.first_name #df["fist_name"] 과 동일하게 출력
'''
0 Jason
1 Molly
2 Tina
3 Jake
4 Amy
Name: first_name, dtype: object
'''
loc - index location / index 이름 (ex. 전체 데이터 프레임에서 인덱스 이름이 0인 행만 추출해줘)
iloc[행 인덱스, 열 인덱스] - index position / index number (ex. 전체 데이터 프레임에서 0번째 행에 있는 값들만 추출해줘)
df.loc[1]
'''
first_name Molly
last_name Jacobson
age 52
city Baltimore
debt NaN
Name: 1, dtype: object
'''
df["age"].iloc[1:]
'''
1 52
2 36
3 24
4 73
Name: age, dtype: int64
'''
# Example from - https://stackoverflow.com/questions/31593201/pandas-iloc-vs-ix-vs-loc-explanation
s = pd.Series(np.nan, index=[49,48,47,46,45, 1, 2, 3, 4, 5])
s
'''
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
4 NaN
5 NaN
dtype: float64
'''s.loc[:3]
'''
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
dtype: float64
'''s.iloc[:3]
'''
49 NaN
48 NaN
47 NaN
dtype: float64
'''
Transpose
df.T
csv 변환
df.to_csv()
column 삭제
del df["first_name"]3. Selection & Drop
- column 이름 없이 사용하는 index number은 row 기준 표시
df[:3]
'''
first_name last_name age city
0 Jason Miller 42 San Francisco
1 Molly Jacobson 52 Baltimore
2 Tina Ali 36 Miami
'''
- column 이름과 함께 row index 사용시, 해당 column만
df["first_name"][:2]
'''
0 Jason
1 Molly
Name: first_name, dtype: object
'''
df[["first_name", "last_name"]][:1]
'''
first_name last_name
0 Jason Miller
'''
df.iloc[:2,:2]
'''
first_name last_name
0 Jason Miller
1 Molly Jacobson
'''df.loc[[1,2],["age","city"]]
'''
age city
1 52 Baltimore
2 36 Miami
'''
- index number로 drop (row)
df.drop(2)
'''
first_name last_name age city
0 Jason Miller 42 San Francisco
1 Molly Jacobson 52 Baltimore
3 Jake Milner 24 Douglas
4 Amy Cooze 73 Boston
'''
- axis 지정으로 축을 기준으로 drop
df.drop("age", axis = 1)
'''
first_name last_name city
0 Jason Miller San Francisco
1 Molly Jacobson Baltimore
2 Tina Ali Miami
3 Jake Milner Douglas
4 Amy Cooze Boston
'''4. Dataframe operation
Series operation
- index를 기준으로 연산 수행. 겹치는 index가 없을 경우 NaN 값으로 반환
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
s1 = Series(range(1,6), index=list("abced"))
'''
a 1
b 2
c 3
e 4
d 5
dtype: int64
'''
s2 = Series(range(5,11), index=list("bcedef"))
'''
b 5
c 6
e 7
d 8
e 9
f 10
dtype: int64
'''
s1+s2 # s1.add(s2) 와 결과 동일
'''
a NaN
b 7.0
c 9.0
d 13.0
e 11.0
e 13.0
f NaN
dtype: float64
'''
Dataframe operation : add, sub, div, mul
- df는 column과 index를 모두 고려
- add operation을 쓰면 NaN 값 0으로 변환
df1 = DataFrame(
np.arange(9).reshape(3,3),
columns=list("abc"))
'''
a b c
0 0 1 2
1 3 4 5
2 6 7 8
'''
df2 = DataFrame(
np.arange(16).reshape(4,4),
columns=list("abcd"))
'''
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
'''
df1+df2
'''
a b c d
0 0.0 2.0 4.0 NaN
1 7.0 9.0 11.0 NaN
2 14.0 16.0 18.0 NaN
3 NaN NaN NaN NaN
'''
df1.add(df2, fill_value = 0)
'''
a b c d
0 0.0 2.0 4.0 3.0
1 7.0 9.0 11.0 7.0
2 14.0 16.0 18.0 11.0
3 12.0 13.0 14.0 15.0
'''
Series + Dataframe
- column 기준
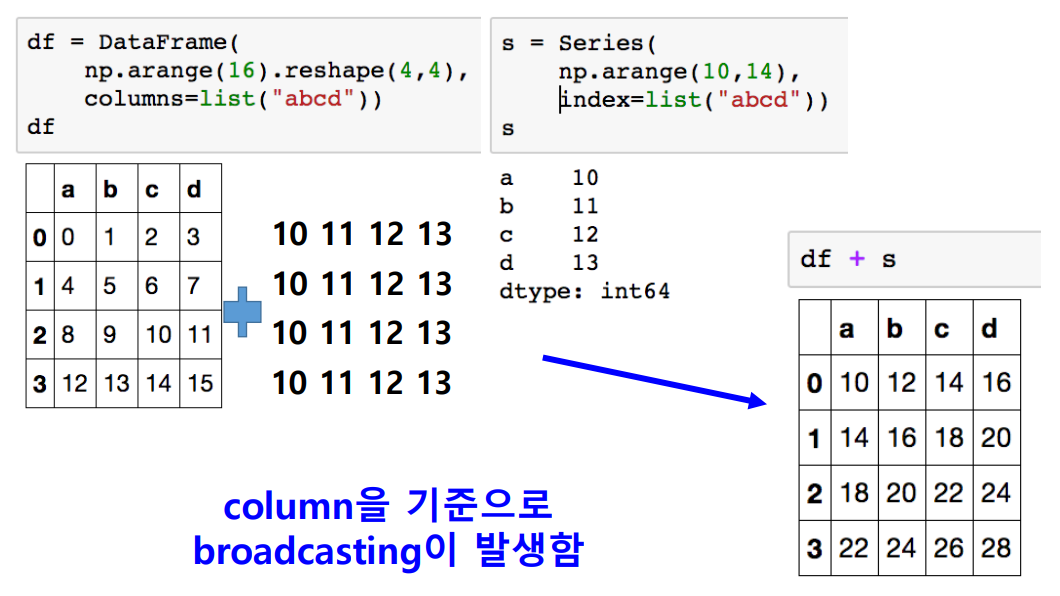
- row 기준 (axis 사용)
