~week12 면접 준비
용어 정리
Q. One Hot 인코딩에 대해 설명해주세요
One hot 인코딩이란 ‘단 하나의 값만 True이고 나머지는 모두 False인 인코딩’이다.
이 과정을 거치면 데이터 형태는 0-1로 이루어졌기 때문에 컴퓨터가 인식하고 학습하기에 용이하다
예시)
강아지는 0번 인덱스, 고양이는 1번 인덱스, 냉장고는 2번 인덱스를 부여했다고 할 때,
강아지 = [1, 0, 0] /고양이 = [0, 1, 0] / 냉장고 = [0, 0, 1]
총 선택지가 전부 3차원 벡터가 됨. 그리고 각 선택지의 벡터들을 보면 해당 선택지의 인덱스에만 1의 값을 가지고, 나머지 원소들은 0의 값을 가짐. 이렇게 one hot encoding으로 표현된 벡터를 one-hot vector라고 함
꼭 실제값을 원-핫 벡터로 표현해야만 다중 클래스 분류 문제를 풀 수 있는 것은 아니지만,
대부분의 다중 클래스 분류 문제는 각 클래스 간 관계가 균등해서 one hot vector를 사용하면 유용함
그리고 다수의 클래스를 분류할 때는 클래스의 개수만큼 숫자 레이블이 필요
ex) {red, green, blue} 라면 1,2,3로 레이블 가능
딥러닝
Q. 뉴럴넷의 가장 큰 단점은 무엇인가? 이를 위해 나온 One-Shot Learning은 무엇인가?
뉴럴넷은 고차원의 데이터에 대해서 좋은 성능을 보이지만 이는 일반적으로 학습데이터의 양이 많을 때에 해당됩니다.
현실에서는 충분한 데이터를 구하지 못할 경우가 더 많습니다.
이러한 문제를 해결하기 위해 고안된 방법이 소량의 데이터만으로 학습을 할 수 있게 하는 Few-shot learning이고 One-shot learning은 few-shot learning의 극단적인 예시로, 한 장의 데이터만으로 학습을 할 수 있게 하는 학습 방법입니다.
예를 들면, 보통 얼굴 인식 시스템은 데이터베이스에 직원 혹은 팀원이 사진이 하나밖에 없는 경우가 많기 때문에 One-shot learning을 적용합니다. Distance function을 이용해 D(Image1, Image2) <= k 인 경우 같은 사람이라고 예측하고, > k 인 경우 다른 사람이라고 예측하도록 학습합니다.
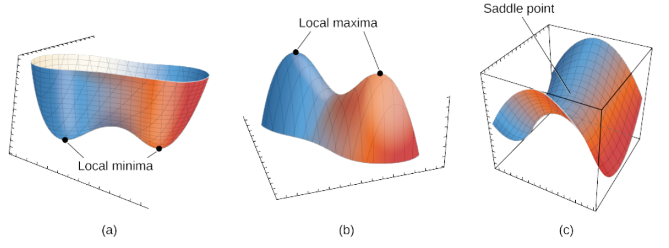
Q. Local Minima 문제에도 불구하고 딥러닝이 잘 되는 이유는?
local minima는 사실상 고차원 공간에서 발생하기 어렵기 때문에 딥러닝에서는 local minima의 큰 영향을 받지 않습니다.
왜냐하면 실제 딥러닝 모델에서는 엄청난 수의 weight가 있는데, 이 weight들이 모두 local minima에 빠져야 weight update가 정지 되기 때문입니다.
그리고 실험적으로 알려진 결과에 따르면 local minima가 발생하더라도 이는 사실 global minima에 유사하기 때문에 큰 문제가 되지 않습니다.
Q. Gradient Descent가 Local Minima 문제를 피하는 방법은?
GD에 momentum(관성)을 적용하거나 learning rate를 조절하는 등 local minima 문제를 피하려는 방법들이 많이 제안되고 있습니다. 최근에는 momentum과 lr 조절을 모두 적용하는 Adam, AdamW optimizer를 많이 사용하고 있습니다.
Q. 찾은 해가 Global Minimum인지 아닌지 알 수 있는 방법은?
딥러닝에서 다루는 문제가 convexity를 만족하지 않아 찾은 해가 global Minima인지 정확하게 알 수 없습니다.
하지만, 고차원의 공간에서 발생하는 critical point(일차 미분이 0인 지점)는 거의 대부분 saddle point이기 때문에,
만일 saddle point가 아닌 경우는 global minimum이거나 또는 global minimum과 유사한 수준의 local minima라고 생각할 수 있습니다.
* saddle point: 다변수 실함수의 변역에서, 어느 방향에서 보면 극대값이지만 다른 방향에서 보면 극소값이 되는 점이다.
Gradient Descent
Q. SGD, RMSprop, Adam에 대해서 설명하시오.
1.
SGD는 Stochastic Gradient Descent의 약자로 Loss Function의 값을 계산할 때 전체 train set을 사용하는 Batch Gradient Descent와 달리 데이터 한개 또는 일부 데이터의 모음(mini-batch) 에 대해서 loss function을 계산하는 방법입니다. (데이터 한 개를 사용하는 경우를 SGD, mini-batch를 사용하는 경우를 SGD라고 하지만 오늘날의 딥러닝에서 일반적으로 통용되는 SGD는 mini-batch SGD입니다.)
SGD는 Batch Gradient Descent 처럼 모든 데이터에 대한 계산이 이루어지지는 않기 때문에 Batch Gradient Descent보다 다소 부정확할 수는 있지만 계산 속도가 훨씬 빠르기 때문에 같은 시간에 더 많은 step의 학습을 진행할 수 있으며 step을 반복하게 되면 Batch의 결과와 유사한 결과로 수렴합니다.
또한 SGD를 사용할 경우 shooting이 일어나기 때문에 Batch Gradient Descent와 달리 local minima에 빠질 위험이 적습니다. 그러나 SGD는 비등방성 함수에서는 기울기에 따라 지그재그로 움직여 최적해를 찾는데 오히려 더 많은 시간이 소요될 수도 있습니다. 또한 고차원으로 갈수록 saddle point에 빠질 수 있는 문제점이 있습니다.
2.
Momentum 은 기존 weight에 이전의 gradient($v$)도 반영하는 방법입니다.
$\alpha$(모멘텀 계수)는 이전 gradient를 얼마나 고려할 것인지를 의미하고 일반적으로 0.9, 0.99 같은 값을 사용합니다. 이전 gradient도 반영하기 때문에 local minima나 saddle point에 빠지더라도 관성의 영향을 받아 탈출할 수 있습니다.
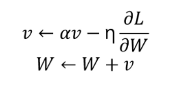
Momentum이 어느 방향으로 갈지에 대한 방법이라면 Adagrad 는 한번에 얼만큼 갈지에 대한 방법입니다. Momentum은 optimum에 가까워져도 learning rate가 늘 일괄적으로 적용되기 때문에 지나치게 될 수 있습니다. Adagrad는 Adaptive gradient의 약어로 이름에서도 알 수 있듯이 지금까지 많이 변화한 매개변수는 적게 변화하도록, 반대로 적게 변화한 매개변수는 많이 변화하도록 learning late의 값을 조절하는 기법입니다.
t번째 time step 까지의 기울기를 누적한 값 $G_{t}$를 계산하고 이 값의 제곱근 역수를 학습률에 곱해줍니다. 이 때 $G_{t}$ 값이 0인 경우 값이 무한대로 발산할 수 있기 때문에 이를 방지하기 위해 $\epsilon$을 더해줍니다.
그러나 $G_{t}$값이 누적되면서 점차 커지기 때문에 오래 학습을 진행하면 학습률이 0에 가까워져 더 이상 학습을 진행하지 못하게 되는 문제점이 있습니다.

3.
Adagrad의 문제점을 해결하기 위해 제안된 기법이 RMSprop 입니다. RMSprop은 decay rate를 적용하여 기존에 그대로 누적되던 $G_{t}$값을 decay하여 해당 값이 무한정 커지는 것을 방지하기 때문에 더 오래 학습할 수 있습니다.
4.
Adam 은 어느 방향으로 갈지에 대한 방법인 Momentum과 얼만큼 갈지에 대한 방법인 RMSprop의 장점을 결합한 기법입니다. 기존 Momentum 항과 RMSprop항의 차이는 각각 지수이동평균값을 곱해주었다는 점인데 지수이동평균으로 오래전 time step의 값은 적게 반영하고 최근 step의 값을 많이 반영할 수 있습니다. 또한 학습 초기에는 모멘텀 항 값과 RMSprop 항 값이 0으로 설정되어 있고 (1−β1)∇f(xt−1)과 (1−β2)(∇f(xt−1))2이 너무 작기 때문에 0에 수렴하는 것을 방지하기 위해 편향 보정을 적용해줍니다. 학습이 계속 진행되다보면 (1−β1)와 (1−β2)는 거의 1에 가까워지기 때문에 hat_m_{t}와 hat_g_{t}는 나중에 m_{t}, g_{t}와 같은 값이 됩니다.
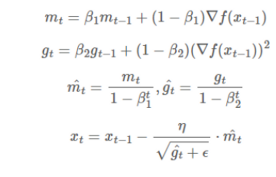
Q. Mini batch를 작게 할 때의 장단점은?
배치 사이즈는 학습 시 정해야하는 하이퍼 파라미터로 이것에 따라 학습 양상과 결과가 달라질 수 있습니다.
Batch size를 작게 하는 경우 sample의 수가 적어 training set의 분포에 근사하게 추정되지 않기 때문에 noise가 많아져 generalization 효과를 줄 수 있다는 장점이 있습니다.또한 최소 요구 메모리 양이 줄어듭니다.
그러나 배치 사이즈가 작을 수록 학습에 걸리는 시간은 늘어나게 된다는 단점이 있습니다.
클러스터링 알고리즘
Q. 클러스터링 알고리즘이란? 어디에 사용되는 가?
클러스터링 알고리즘은 레이블이 없는 데이터 안에서 패턴과 구조를 발견하는 비지도 학습 기술 중 하나이다.
클러스터링 알고리즘은 추천 엔진이나 시장 세분화에 사용할 수 있다.
1. 추천 엔진: 개인화된 사용자 경험을 제공하기 위한 상품들의 그룹화
2. 시장 세분화: 지역,인구,행동 등을 바탕으로 고객들을 그룹화
Q. K-means 알고리즘이란?
K-means 알고리즘은 특성이 비슷한 데이터를 같은 그룹으로 묶어주는 클러스터링 알고리즘이다.
K개의 군집(클러스터) 개수를 만들기 위해 K개의 임의의 중심점을 배치한 뒤, 각 데이터들을 가장 가까운 중심점으로 할당하여 군집을 형성한다. 군집으로 할당된 데이터들을 기반으로 해당 군집의 중심점을 업데이트한다. 이 과정을 중심점이 수렴할 때까지 반복한다.
Q. K-means의 단점은?
1. 사용자가 초기에 설정해 주어야하는 군집의 개수 K의 값에 따라 성능이 달라진다.
2. 각 데이터들과의 거리를 기준으로 군집의 중심점을 업데이트하므로 데이터의 노이즈에 민감하다.
3. 계산량이 많다. 중심점과 각각의 데이터의 거리를 전부 측정해야 하므로 계산량이 많다.
4. 원(혹은 구)형(spherical)의 cluster만 찾을 수 있다. 아래 예시와 같이 cluster의 모양이 원형이 아닐 때는 정확한 결과를 도출하지 못한다.

Q. K-means 알고리즘과 K-NN 알고리즘의 차이점은?
두 알고리즘 모두 K개의 점을 지정하여 거리를 기반으로 구현되는 알고리즘이지만
K-NN 알고리즘은 지도학습 방법이고 K-Means는 비지도 학습 방법이다.
Q. Weight Initialization을 왜 사용하나요?
만약 초기 Weight 값이 0이라면 학습이 불가능할 것이며, 처음부터 Weight 값이 최적의 값들이라면 gradient 값이 작더라도 좋은 모델을 만들 수 있을 것입니다.
만약 Weight 값들을 평균 0, 표준편차 1인 표준 정규분포로 초기화 한 경우 Sigmoid 함수의 출력 값이 0과 1에 치우치게 됩니다. 출력 값이 0과 1에 치우치게 되면 Gradient는 0에 가까운 값을 갖게 되므로 Gradient Vanishing 문제가 일어날 수 있습니다.
따라서 Weight를 잘 설정하여 출력 값의 분포를 안정화시켜주는 것이 중요합니다.
Q. Weight Initialization 방법에 대해 말해주세요. 그리고 무엇을 많이 사용하나요?
Weight Initalization 방법으로는 Xavier Initalization과 He Initalization 방법이 있습니다.
Xavier Initalization 방법은 표준 정규 분포를 입력 개수의 표준편차로 나누어주는 방법입니다. 층마다 노드 개수가 다르더라도 이에 맞게 가중치가 초기화되기 때문에 고정된 표준편차를 사용하는 것보다 훨씬 더 강건(Robust)합니다. 이 방법은 Sigmoid나 Tanh 함수를 거친 출력 값들이 표준 정규 분포 형태를 가질 수 있어서 Sigmoid나 Tanh를 activation function으로 사용할 때 많이 사용합니다.
그러나 Xavier Initalization을 하고 ReLU 함수를 activation Function으로 사용하게 되면 출력 값이 평균과 표준편차 모두 0으로 수렴하게 됩니다.
ReLU 함수에 적합한 Initalization 방법은 He Initalization 입니다. He Initalization은 표준 정규 분포를 입력 개수의 절반의 제곱근으로 나누어주는 방법입니다.
따라서 Activation Function으로 Sigmoid나 Tanh를 사용할 경우에는 Xavier Initalization을, ReLU를 사용할 때는 He Initalization을 많이 사용합니다.
상식적인 질문
Q. 딥러닝할 때 GPU를 쓰면 좋은 이유는?
GPU를 사용하면 효율적으로 최적화 할 수 있다. 왜냐하면 딥러닝 알고리즘은 많은 양의 사칙 연산을 수행하는데, GPU는 이러한 행렬 곱셈 등의 사칙 연산에 특화되어 있다. 따라서 GPU를 통해 동시에 여러 코어에서 계산이 가능하다.
Q. CPU VS GPU
ALU는 산술연산을 진행하는 장치이다.
CPU에는 제어장치(CU)가 존재하는 대신, ALU가 1개 뿐이다. 반면 GPU는 CU가 없고, ALU가 여러 개이다. (CPU가 GPU에 명령을 내린다)
많은 양의 단순 사칙 연산 수행은 GPU의 성능이 더 좋지만, GPU는 복잡한 연산은 진행하지 못한다.

Q. 학습 시 필요한 GPU 메모리는 어떻게 계산하는가?

Q. 학습 중인데 GPU를 100% 사용하지 않고 있다. 이유는?
GPU를 100% 활용하지 못하는 경우는 두 가지로 나뉜다.
첫 번째는 GPU의 그래픽 메모리를 충분히 활용하지 못하는 경우, 두 번째는 GPU의 연산 능력을 충분히 활용하지 못하는 경우이다.
(1) 그래픽 메모리가 100%가 아닌 경우, 작은 Batch Size가 문제일 수 있다.
또는 Multi-GPU 환경에서 Data Parallel 방법으로 GPU 로드를 분산할 시, 각 GPU의 output을 하나의 GPU로 모아서 loss 계산을 하여 GPU 메모리 사용량의 불균형이 발생할 수 있다.
(2) 연산 능력이 100%가 아닌 경우에는 모델의 계산 과정에서 CPU 병목이 원인일 수 있다.
*병목(bottleneck) 현상: 두 구성 요소의 최대 성능의 차이로 인해 한 구성 요소가 다른 하드웨어의 잠재 성능을 제한하는 것
Q. GPU를 두개 다 쓰고 싶다. 방법은?
두 개 이상의 GPU를 사용하려면 딥러닝 라이브러리가 제공하는 분산(distribution) 기능을 사용해야 한다. 인풋 데이터를 여러개의 GPU로 순전파를 하고 역전파 시 GPU들의 기울기 합을 평균을 내 이 평균값으로 가중치 업데이트를 한다.
수학
Q. “likelihood”와 “probability”의 차이는 무엇일까요?
확률(probability)는 주어진 모델(분포)을 기반으로 어떤 데이터가 관측될 확률을 말하는 반면에
우도(likelihood)는 데이터들이 관측되었을 때 이들이 특정 모델(분포)과 일치하는, 해당 모델을 지지하는 정도를 말한다.
예를 들어 확률은 동전의 앞면 뒷면이 각각 반반의 절반씩 나올 때에 앞면이 연속해서 몇번 나올지를 따지는 반면에,
우도의 경우 동전의 앞면이 총 10번중에 4번 나왔을 때 동전의 앞/뒷면 등장 확률이 각각 0.5일 가능성을 따진다.
확률 : 어떤 시행(trial, experiment)에서 특정 결과(sample)가 나올 가능성. 즉, 시행 전 모든 경우의 수의 가능성은 정해져 있으며 그 총합은 1(100%)이다.
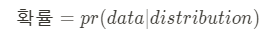
가능도 : 어떤 시행(trial, experiment)을 충분히 수행한 뒤 그 결과(sample)를 토대로 경우의 수의 가능성을 도출하는 것. 아무리 충분히 수행해도 어디까지나 추론(inference)이기 때문에 가능성의 합이 1이 되지 않을 수도 있다.
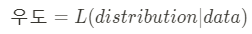
파이썬
Q. 파이썬을 언어로 사용함에 있어 누릴 수 있는 혜택은?
1. 파이썬은 하이레벨 프로그래밍 언어로 코드를 쓰고 읽기가 비교적 쉬운 편이다. 즉 코드를 작성하고 분석하는 시간을 줄여 모델링을 하는 데 더 집중할 수 있다.
2. 다양한 라이브러리를 지원한다. 모든 운영체제에서 사용 가능하다.
파이썬은 도메인을 가리지 않고 사용할 수 있다. 데이터 전처리부터 모델링, 앱 개발까지 분야에 구애되지 않고 파이썬으로 프로그래밍할 수 있기 때문에 전분야에 걸쳐 라이브러리가 많이 개발되어 있으며 머신러닝, 딥러닝 서비스 개발 시 시간을 단축할 수 있다.
Q. 파이썬의 Generator에 대해 설명해주세요
파이썬의 Generator는 시퀀스의 요소를 하나씩 차례대로 순회하면서 값을 생성하는 객체인 Iterator를 생성해주는 함수입니다. Generator는 yield를 키워드를 사용해 생성할 수 있습니다.
Generator는 next 함수로 호출할 때마다 값을 생성하고 해당 값을 메모리에 올리기 때문에 대용량 데이터를 처리할 때 메모리를 효율적으로 사용할 수 있습니다.
def test_generator():
yield 1
yield 2
yield 3
gen = test_generator()
print(type(gen)) # <class 'generator'>
print(next(gen)) # 1
print(next(gen)) # 2
print(next(gen)) # 3
print(next(gen)) # error
'''
Traceback (most recent call last):
File "c:\Users\2jeon\OneDrive\바탕 화면\codingtest\test.py", line 11, in <module>
print(next(gen))
StopIteration
'''
Q. set와 dictionary의 차이점은 무엇인가?
딕셔너리와 세트는 순서가 없다는 공통점이 있습니다. 세트와 딕셔너리는 특정 요소가 포함되어 있는 지 확인할 때 유용합니다. 딕셔너리는 특히 key값으로 빠르게 원하는 데이터를 얻을 수 있습니다.
세트는 중복을 허용하지 않습니다.
딕셔너리는 key/value 쌍으로 이루어진 자료구조로, key는 추가할 수 있지만 수정할 수는 없습니다.
세트는 immutable한 자료형만 요소로 받아들이지만, 딕셔너리는 mutable/immutable 제한 없이 데이터를 저장할 수 있습니다.
Q. list와 tuple의 차이점은?
리스트는 요소를 삭제하거나 변경할 수 있다(mutable). []로 작성
튜플은 요소를 삭제하거나 변경할 수 없다.(immutable). ()로 작성
Q. sort()와 sorted() 함수의 차이점은?
sort()의 특징
list의 내장함수로 None을 반환하는 대신 기존 list 객체 자체를 정렬한다. 리스트에서만 쓸 수 있다.
리스트는 mutable 한 객체이므로 sort() 메서드를 사용하면, 기존 리스트는 정렬된 리스트로 대체된다.
sorted()의 특징
파이썬의 내장함수로 입력 받은 iterable 객체와 별도로 정렬된 객체를 반환한다. iterable 객체면 전부 사용가능하다. (리스트, 문자열, 딕셔너리, 집합...)
새로운 리스트 객체를 리턴한다
파이썬 sort(), sorted() 함수는 Tim Peters라는 사람이 만든 알고리즘인 tim sort 알고리즘을 사용한다. 이는 병합정렬과 삽입정렬의 아이디어를 적절히 섞어서 만든 알고리즘으로 O(NlogN)의 시간복잡도를 가진다.
Q. 피클링(pickling)과 언피클링(unpickling)은 무엇인가?
'pickle'은 파이썬 객체를 파일로 저장하고 불러오는데 쓰이는 모듈이다.
파이썬 객체를 파일로 변환하는 과정은 Pickling이라고 하고 반대로 파일을 불러올 경우 unpickling이라고 한다.

