ML Ops
<목차>
1. ML Ops란
2. ML Ops의 구성요소
- 인프라
- Serving
- Experiment, Model Management
- Feature Store
- Data Validation(Data Management)
- Continuous Training
- Monitoring
- AutoML
3. 추가내용 정리
- 용어
- Online Serving
[복습]
모델 개발 프로세스
문제 정의 EDA Feature Engineering Train Predict Deploy(배포)
- Feature Engineering(특징 공학) : 모델 정확도를 높이기 위해 주어진 데이터를 예측 모델의 문제를 잘 표현할 수 있는 feature로 변형 시킨다. 즉, 주어진 데이터로부터 모델링 성능을 높이는 새로운 특성을 만든다.
- 모델이 배포됐을 때는 다양한 문제가 발생할 수 있다. 예를 들면
1. 모델의 결과값이 이상할 수 있다. 리서치를 할 때 outlier로 이상한 input 데이터를 제외했지만 실제 서비스에서는 그렇지 못하기 때문이다.
2. 모델의 성능이 계속 변경될 수 있다. 예측 값과 실제 레이블을 알아야 하는데, 정형(Tabular) 데이터가 아닌 비정형 데이터에선 이를 알기 어렵다.
3. 새로운 모델이 더 안 좋은 경우가 있다. Research 환경에서는 성능이 좋았더라도 Production 환경에서 좋지 않을 수 있고, 이런 경우 이전 모델로 되돌리기 위한 작업이 필요하다.
ML Ops란
ML(Machine Learing) + Ops (Operations)
ML Ops는 머신 러닝 모델을 운영하면서 반복적으로 필요한 업무를 자동화시키는 과정을 일컫는다
모델링에 집중할 수 있도록 관련 인프라를 만든다.
ML Ops의 등장 배경과 목표
최근에는 비즈니스 문제에 머신러닝, 딥러닝을 적용하는 경우가 많아졌는데
이렇게 production 환경에서 배포하는 과정에서는 research의 모델이 재현 가능해야 하고,
현실의 리스크가 있는 환경에서 모델이 잘 동작해야 한다.
따라서, ML Ops는 빠른 시간 내에 가장 적은 위험을 부담하여
아이디어부터 production 단계까지 ML 프로젝트를 진행할 수 있도록
기술적 마찰을 줄이는 것을 목표로 한다.
그리고 모델 개발과 운영에서의 반복을 최소화하여 비즈니스 가치를 창출하고자 한다.
ML Ops의 구성요소
1. 인프라 (서버, GPU) 어떤 레스토랑에서 타코를 팔까
인프라는 환경을 운영하고 관리하는데 필요한 구성 요소를 뜻한다. 아래와 같은 고려 사항이 있다.
- 예상되는 트래픽은 얼마인가
- 서버의 CPU, Memory 성능은 어느 정도로 할 것인가
- 스케일 업, 스케일 아웃이 가능한가
- 자체 서버를 구축할 것인가, 클라우드를 사용할 것인가
2. Serving 손님에게 어떻게 타코를 서빙할까
서빙은 production 환경 (실제 환경)에 모델을 사용할 수 있도록 배포하는 것이다.
즉, 웹이나 앱에서 머신 러닝 모델을 사용할 수 있도록 한다.
Serving VS Inference
서빙은 모델을 활용하는 방식, 모델을 서비스화하는 관점에서 쓰이는 용어이고,
Inference는 모델에 데이터가 제공되어 이를 예측, 사용하는 관점에서 사용되는 용어이다.
Batch Serving과 Batch Inference는 혼용되어 사용되기도 하나
Online Serving과 Online Inference는 구분되어 사용해야 한다.
Serving은 크게 online serving과 batch serving, (모바일, IoT 기기에서의) Edge Serving 세 가지 방식으로 나뉜다.

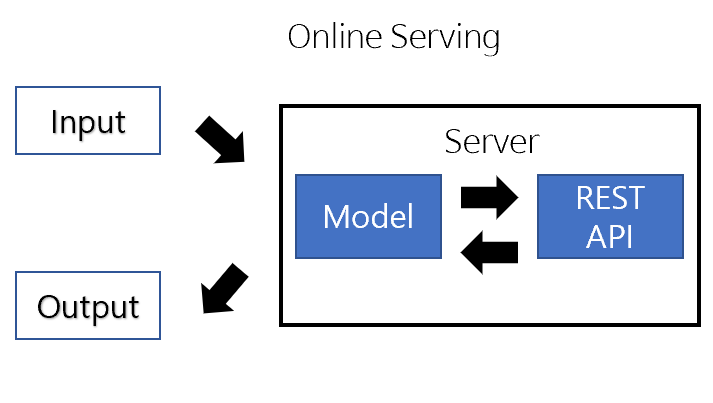
Online serving은 요청이 올 때마다 실시간으로 서비스를 진행하는 것이다. 엄밀히 따지면 아래와 같은 그림임.
Client가 ML 모델 서버로 HTTP 요청(Request) → 서버 내 ML 모델 inference → 예측값 반환(Response)
Batch serving은 일정 주기를 기준으로 서비스를 진행하는 것이다. 따라서 실시간이 필요없는 곳에서 사용된다.
Workflow Scheduler가 특정 기간동안 작업을 실행하는 역할을 담당한다.
ex) Airflow, Cron Job으로 스케줄링 작업

3. Experiment, Model Management 여러 레시피를 만들어보고 관련 과정들을 기록해둔다
Model Management : 실험 관련 정보들이 코드 상 알아서 저장되도록 한다.
ex. ML flow
from pprint import pprint
import numpy as np
from sklearn.linear_model import LinearRegression
import mlflow
from utils import fetch_logged_data
def main():
# enable autologging
mlflow.sklearn.autolog()
# prepare training data
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]])
y = np.dot(X, np.array([1, 2])) + 3
# train a model
model = LinearRegression()
with mlflow.start_run() as run:
model.fit(X, y)
print("Logged data and model in run {}".format(run.info.run_id))
# show logged data
for key, data in fetch_logged_data(run.info.run_id).items():
print("\n---------- logged {} ----------".format(key))
pprint(data)
4. Feature Store 사용되는 재료들을 미리 만들어서 저장해둔다
Feature Store은 feature의 특성에 따라 효율적으로 가공, 저장 그리고 관리할 수 있는 시스템이다. 아래 사진 출처

ex) Feast
Feast는 feature store을 어떻게 만들고 가져올 지를 설정한다.
from pprint import pprint
from feast import FeatureStore
store = FeatureStore(repo_path=".")
feature_vector = store.get_online_features(
features=[
'driver_hourly_stats:conv_rate',
'driver_hourly_stats:acc_rate',
'driver_hourly_stats:avg_daily_trips'
],
entity_rows=[{"driver_id": 1001}]
).to_dict()
pprint(feature_vector)
# Make prediction
# model.predict(feature_vector)Stream source는 실시간 데이터이고,
Batch source는 데이터 베이스, 파일 등에 저장되어 data warehouse로부터 불러오는 데이터이다,
실시간 예측에는 Stream을 쓰려고 하나 학습할 때 Stream을 못 쓰는 경우가 있다.


5. Data Validation (Data Management) 현재의 재료가 예전에 사용한 재료와 동일한지 확인
Feature의 분포를 확인한다. 아래의 왼쪽 사진이 아닌 오른쪽처럼 되도록 한다.

ex) TFDV, AWS Deequ
6. Continuous Training 메뉴의 인기가 떨어지면 신선한 재료로 다시 만든다
새로운 데이터가 들어온 경우, 일정 기간마다, metric 값에 큰 변동이 있는 경우 등에 retrain을 진행한다.

7. Monitoring 레스토랑의 매출, 손님수 등을 기록한다
모델의 지표, 인프라의 성능 지표를 계속해서 기록해 나간다.
8. AutoML 자동으로 요리되는 에어프라이어
ex) microsoft nni
[용어 정리]
Web server : client로 부터 request를 받으면 요청한 내용을 보내는(response) 프로그램
모든 웹 서버는 request와 response로 나뉜다
ML Model server : 어떤 데이터를 제공하면서 예측해달라고 요청하면, 모델을 사용해 예측값을 반환하는 서버
API(Application Programming Interface) :
운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스.
특정 서비스에서 해당 기능을 사용할 수 있도록 외부에 노출하는 역할 뿐만 아니라 (ex. 기상청 API, 지도 API)
Pandas, Tensorflow, PyTorch와 같은 라이브러리 함수도 API에 속한다
인터페이스 : 기계와 인간의 소통 창구
Online Serving
- 전처리 서버/ ML모델 서버로 분리할 수도 있고, ML 모델 서버에서 전처리도 함께 진행하기도 한다
- 서비스 서버에 ML서버를 포함하는 경우도 있고, ML서버를 별도로 운영하는 경우도 존재한다.
- Online Serving에서 중요한 건 "지연 시간(latency)를 최소화" 해야 한다.
Latency : 하나의 예측을 요청하고 반환값을 받는데까지 걸리는 시간
<Online Serving 구현 방식>
1) 직접 API 웹 서버 개발 : Flask, FastAPI 등을 사용해 서버 구축
2) 클라우드 서비스 활용 : AWS의 SageMaker, GCP의 vertex AI 등
장점: 직접 구축해야 하는 MLOps의 다양한 부분(ex. API 서버 만들기)이 만들어짐
사용자 관점에선 PyTorch 사용하듯 학습 코드만 제공하면 API 서버가 만들어짐
단점: 비용 문제
클라우드 서비스가 익숙해야 잘 활용할 수 있음
3) Serving 라이브러리 활용 : TF Serving, Torch Serve, MLFlow, BentoML 등
# *** BentoML 예시 ***
# 아래 코드 실행, 학습 후 CLI에서 아래 명령어 입력하면 배포 끝
# bentoml serve IrisClassified:latest
from iris_classifier import IrisClassifier
iris_classifier_service = IrisClassifier() # create a classifier instance
iris_classifier_service.pack('model', clf) # pack the newly trained model artifact
saved_path = iris_classifier_service.save() # save the prediction service to disk for model serving
Batch Serving
- batch serving에 관한 라이브러리는 따로 존재하지 않는다.
장점: Jupyter Notebook에 작성한 코드를 함수화한 후, 주기적으로 실행하는 간단한 구조로,
Online Serving보다 구현이 수월하며, 간단함 한번에 많은 데이터를 처리하므로 Latency가 문제되지 않음
단점: 실시간으로 활용할 수 없음
Cold Start 오늘 새로 생긴 컨텐츠는 추천할 수 없음
Cold Start란?
추천 시스템이 새로운 또는 어떤 유저들에 대한 충분한 정보가 수집된 상태가 아니라서
해당 유저들에게 적절한 제품을 추천해주지 못하는 문제를 말한다.
구글의 머신러닝 규칙
머신러닝 전의 규칙은 예상치 못했어서 읽으면서 놀랐다.
프로젝트 주제를 정하다보면 경험해보고 싶은 기술을 먼저 정하고 그에 맞는 아이디어를 떠오르는, 주객이 전도된 경험이 많은데,
그러다보니 현업에서는 어떤 문제 해결이나 니즈를 위해 프로젝트를 진행하고, 필요한 부분에 머신러닝을 접목한다는 걸 간과했다.
[머신러닝 전]
규칙 #1. 머신러닝 없이 제품을 출시하는 것을 두려워하지 말라.
제품에 머신러닝이 반드시 필요하지 않다면 데이터를 확보할 때까지 사용하지 마세요.
규칙 #2. 먼저 측정항목을 설계하고 구현하세요.
머신러닝 시스템의 기능을 공식화하기 전에 현재 시스템에서 최대한 많이 추적하세요. => 최적의 상황을 손 놓고 기다릴 수 없으니 현재 상황에서 최선으로 시행
- 그보다 일찍 시스템 사용자에게서 권한을 얻는 것이 더 쉽습니다.
- 향후에 문제가 될 수 있다고 생각하는 경우 지금은 이전 데이터를 가져오는 것이 좋습니다.
- 측정항목 계측을 염두에 두고 시스템을 설계하는 경우 향후 더 나아질 것입니다. 특히, 측정항목을 계측하기 위해 로그에서 문자열을 일일이 자르지 않아도 됩니다.
규칙 #3. 단순한 휴리스틱으로 제품을 선보일 수 있습니다.
복잡한 휴리스틱은 유지보수할 수 없습니다. 데이터를 확보하고 기본적으로 달성하려는 목표가 있다면 머신러닝으로 넘어갑니다.
[ML 1단계: 첫 번째 파이프라인]
규칙 #4: 첫 번째 모델을 단순하게 유지하고 인프라를 적절하게 유지하세요.
첫 번째 파이프라인을 위한 시스템 인프라에 집중하세요. 앞으로 사용할 창의적인 머신러닝에 대해 생각해 보는 것은 재밌지만, 파이프라인을 먼저 신뢰하지 않으면 어떤 일이 벌어질지 파악하기가 어렵습니다.
규칙 #5: 머신러닝과는 별개로 인프라를 테스트하세요.
시스템의 학습 부분이 캡슐화되어 모든 요소를 테스트할 수 있어야 합니다.
(1) 데이터를 알고리즘으로 가져오는 것을 테스트합니다. 채워야 하는 특성 열이 채워지는지 확인합니다.
(2) 학습 알고리즘에서 모델 가져오기 테스트 학습 환경의 모델이 서빙 환경의 모델과 동일한 점수인지 확인합니다
규칙 #6: 파이프라인을 복사할 때 데이터 드롭(삭제)에 주의하세요.
규칙 #7: 휴리스틱을 특성으로 변환하거나 외부에서 처리합니다.
일반적으로 머신러닝으로 해결하려는 문제는 완전히 새로운 것은 아니라 기존 시스템이 있습니다.
이러한 휴리스틱은 머신러닝으로 조정할 때 상승 효과를 가져올 수 있습니다.
기존 휴리스틱을 사용하는 방법에는 4가지가 있습니다.
| 1 | 휴리스틱을 사용하여 전처리합니다. 예를 들어 스팸 필터에서 발신자가 이미 블랙리스트에 포함되어 있다면 '블랙리스트에 추가'가 의미하는 바를 다시 학습하지 마세요. 메시지를 차단합니다. 이 접근 방식은 이진 분류 태스크에 가장 적합합니다. |
| 2 | 휴리스틱 값을 특성으로 만듭니다. 예를 들어 휴리스틱을 사용하여 쿼리 결과의 관련성 점수를 계산하는 경우 이 점수를 특성 값으로 포함할 수 있습니다. 나중에 머신러닝 기술을 사용하여 값을 마사지(예: 값을 유한한 값 중 하나로 변환하거나 다른 특성과 결합)할 수 있지만 휴리스틱으로 생성된 원시 값부터 사용할 수 있습니다. |
| 3 | Mine the raw input of the heuristic. 설치 수, 텍스트의 문자 수, 요일을 결합하는 앱에 휴리스틱이 있는 경우 이러한 요소를 분리하여 이러한 입력을 학습에 별도로 제공하는 것이 좋습니다. 앙상블에 적용되는 기법 중 일부가 여기에 적용됩니다 |
| 4 | 라벨을 수정합니다. 이 옵션은 휴리스틱이 현재 라벨에 포함되지 않은 정보를 캡처한다고 생각되면 선택합니다. 예를 들어 다운로드 수를 최대화하려고 하지만 품질 높은 콘텐츠도 원한다면 앱에 라벨을 받은 평균 별표 수를 곱하면 됩니다. |
이렇게 새 머신러닝 알고리즘에 기존 휴리스틱을 사용하면 원활한 전환을 돕는 데 도움이 될 수 있지만 동일한 효과를 얻는 간단한 방법이 있는지 생각해 보세요.
<모니터링>
일반적으로 알림을 실행 가능한 상태로 만들고 대시보드 페이지를 두는 등 적절한 알림 상태 관리 연습하기
규칙 #8: 시스템의 최신 요구사항 파악
하루가 지난 모델이 사용되면 성능이 얼마나 저하되나요? 1주일 전? 한 분기가 지났나요? 이 정보는 모니터링의 우선순위를 이해하는 데 도움이 될 수 있습니다.
규칙 #9: 모델을 내보내기 전에 문제를 감지합니다.
모델을 내보내기 직전에 상태 검사를 실행합니다. 특히 홀드아웃 데이터 측면에서 모델의 성능이 적절한지 확인해야 합니다. 또는 데이터가 우려되는 경우 모델을 내보내지 마세요. 지속적으로 모델을 배포하는 많은 팀은 내보내기 전에 ROC 곡선(또는 AUC) 아래의 영역을 확인합니다.
규칙 #10: 자동 실패를 관찰하라.
규칙 #11: 특성 열에 소유자 및 문서를 부여합니다.
