N21, N2N, N2M
이전 포스팅에서 N21, N2N, N2M을 크게 비교하고 각 예제를 살펴보았다.
이제 각 문제에 맞는 모델을 살펴보자.
N21
신경망 기반 분류 기술을 구현해보자.
아래의 프로세스 흐름이 전형적인 신경망 기반 훈련/예측의 구조이다.
| Feed Forward and Prediction | 최종 결과물을 얻고 |
| Cost Function | 최종 결과물과 우리가 원하는 결과물의 차이점을 찾은 후 |
| Differentiation(미분) | 그 차이가 무엇으로 인해 생기는 지 |
| Back Propagation | 역으로 추정하며 |
| Weight Update | 새로운 parameter 값을 배움 |
신경망을 디자인할 때 아래의 선 하나하나가 하나의 parameter에 대응한다고 이해하면 된다.

위 실습에서 하위 문제들로는 Reference Representation, Scoring Normalization, cost func design, paramete update가 있다.
Reference Representation : '정답의 label을 어떻게 숫자화할 것인가'이다.
예를 들어, 다음에 또 가려구요! [Positive] => 100, 다신 안 가요 [Negative]=> 0 ..
이런 식으로 숫자화하다보면 주관적인 값이 매겨질 수 있다.
따라서 긍정이면 1, 부정이면 0으로 값을 설정한다. 이 방식은 "one hot representation"과 유사하고, 객관적이지만 정도를 반영할 수 없다는 단점이 있다.
Scoring Normalization : 예측과 정답을 서로 비교하기 위해서 서로 같은 Scale 의 값이어야 한다.

예측값의 scale을 바꿔주기 위해 softmax를 사용하기도 한다.
왜냐하면 softmax는 어떤 값이든 양수 값으로 바꿔주고, 큰 값은 더 크게 만들어주기 때문이다.
Cost func는 반드시 미분가능해야한다.
N21 모델 (Encoder)
N21 문제는 Encoder + Fully Connected Layer 형태의 모델을 사용한다.
Fully Connected Layer가 필요한 이유는 top layer의 hidden state vector을 우리가 원하는 class와 연결시키기 위함이다.
Transformer을 기본 Encoder라고 하면 Encoder 기반 분류기의 구조는 아래와 같다.

이때 pretrained 모델을 재활용할 뿐, 따로 학습시키지 않을 수도 있다.
N21 문제의 Loss function으로는 MSE, Cross Entropy를 사용한다.
N21 에서 ‘1’ 에 해당하는 output 의 성격에 따라 사용되는 Loss function도 달라진다.

자연어 처리 분야에서 MSE는 다양하게 쓰인다.
예를 들면, MRC 문제에서의 정답 위치를 맞추는 문제, 두 문장의 문장 유사도를 맞추는 문제, 추천 정도를 숫자 값으로 맞추는 문제가 있다.
Cross Entropy는 2개의 확률 분포가 얼마나 차이가 나는지를 잘 잡아낼 수 있는 score이다.
N2N 모델 (Encoder)
1.
N2N 문제는 출력 시, 입력과 토큰의 개수를 동일하게 정해야 한다.
IO, BIO, BIOES라는 세 가지 기준으로 토큰화 할 수 있다. BIOES가 가장 구체적이고 체계화되어있다.
- IO: I(label 있음), O(label 없음)
- BIO: B(label 첫 글자), I(label 있음), O(label 없음)
- BIOES: B(label 첫 글자), I(label 있음), E(label 끝 글자), S(label 1 글자), O(label 없음)

2.
Loss function으로는 Cross Entropy를 사용한다.

단, 위와 같이 하지 않고 아래와 같이 각 token별로 적용한다.

Cross Entropy에는 ignore_index라는 변수가 있다.
Loss 값을 계산할 때 yn은 ignore indxe 값이 아니어야 한다.
따라서, Class Label을 -100으로 설정하면 loss 계산을 할 때 자동으로 제외된다.


Wyn은 특정한 label에 가중치를 부여해서 해당 label을 강조하는 역할을 한다.
3.
N2N을 평가하는 방법을 살펴보기 이전에 binary classification의 주요 평가 Metrix를 살펴보자.
(Recall, Precision, F1 score, Accuracy)

N2N의 경우 각 라벨에 대한 위의 결과가 생성되기 때문에 이를 종합하면 된다.
종합하는 방식에는 Macro와 Micro 두 가지가 있다.
| Macro | 모든 label을 고려한다. 각 라벨별 결과 도출 후, 이에 대한 평균 계산 |
| Micro | 전체를 본다. 라벨에 대한 제한 없이, 전체 데이터에 대한 결과 계산 |
그렇지만 Conlleval-2000이라는 공식 평가툴이 있기 때문에 직접 계산할 필요는 없다.
N2M (Encoder + Decoder)
모델 발전 순서: Encoder-Decoder RNN (2014) => Attention + Encoder-Decoder RNN (2015) => Transformers(Multi-head Attentions) (2017)
1.
Attention은 이전의 포스팅에서도 자세히 설명했지만, 복습하자면
"입력 정보에 가중치를 적용하여 정보를 취사 선택하는 방법"이다.
가중치를 더해서 Attention을 적용하는 Additive(Bahdanau) 와 가중치를 곱하는 Multiplicative(Dot-production)의 두 가지 방식으로 나뉜다.
Transformer는 이 Attention으로만 구현된 모델로 N2M task에 특화되었다. Transformer의 종류는 아래와 같다.

BERT와 GPT 모델 구조에 관한 설명은 이 포스팅에 상세히 있다.
| Encoder Only | ex) BERT - 정보를 양방향으로 취합함 - 분류 문제에 주로 활용됨  <학습방법> Masked Language Modeling(MLM): 손상된 문장을 복원하거나, 문장 간의 관계를 유추하며 학습함 |
Decoder Only |
ex) GPT - 정보를 단방향으로 취합함 - 생성 문제에 주로 활용됨  <학습방법> Auto- regression: 생성한 단어를 다시 입력으로 사용하여 모든 단어를 순서대로 예측함 |
| Encoder - Decoder | 1. BART - BERT와 GPT를 결합한 모델 - 손상된 문장을 활용하여 다양한 선학습 방법을 적용하였음 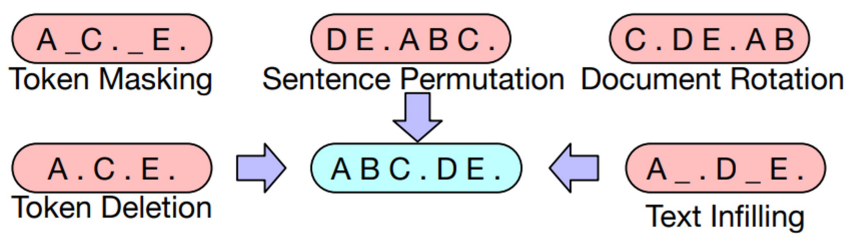 2. T5 - 모든 입출력을 Text로 구성하여 학습함 - 키워드를 활용하여 입력에 태스크 정보를 함께 제공함 |
2.
Decoding 방식에는 대표적으로 Brute force, Beam search, Greedy 등이 있다.

Decoding 결과를 개선하기 위한 방법은 다음과 같다.
- N-gram penalty : 동일한 단어가 반복적으로 생성되는 문제가 있음 => 같은 단어가 N번 이상 연속되지 못하게 제한한다.
- Sampling: 창의성을 부여하기 위해 단어 선택에 랜덤성을 부여한다.
- Random Sampling: 생성될 단어의 확률에 따라 랜덤하게 단어를 선택함
- Top-k: 확률이 높은 K개의 단어를 랜덤하게 선택함
- Top-p: 누적확률이 p이상 되는 단어를 랜덤하게 선택함
3.
Hugging face에는 generate 함수가 있다.

💡
N21 Sentence Topic Classification task를 허깅페이스를 사용해서 수행하자(w. KLUE YNAT 데이터셋)
Huggingface 에 배포된 모델 불러오기
위 실습에서는 klue, kykim, snunlp를 사용했다.
# https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoTokenizer
from transformers import AutoTokenizer
# transformers.AutoTokenizer의 from_pretrained() 함수 실습
# 많은 Tokenizer 가 있으나 이번 실습에서는 3가지 정도를 확인해 보겠습니다.
klue_tokenizer = AutoTokenizer.from_pretrained('klue/bert-base')
kykim_tokenizer = AutoTokenizer.from_pretrained('kykim/bert-kor-base')
snunlp_tokenizer = AutoTokenizer.from_pretrained('snunlp/KR-BERT-char16424')import torch
from transformers import BertForSequenceClassification
# https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertForSequenceClassification
klue = BertForSequenceClassification.from_pretrained('klue/bert-base', num_labels=7)
kykim = BertForSequenceClassification.from_pretrained('kykim/bert-kor-base', num_labels=7)
snunlp = BertForSequenceClassification.from_pretrained('snunlp/KR-BERT-char16424', num_labels=7)모델을 출력해보면 구조를 확인할 수 있다. klue의 모델을 살펴보자.

A 문장일 때 0, B 문장일 때 1 로 token_type은 두 가지이다.
word embedding은 입력 단어수(vocab_size)가 32000개이기 때문이고, position embedding은 model_max_len이 512이기 때문이다.
BertLayer은 0에서 11까지 총 12개이다. 마지막에는 Tanh를 적용해서 값을 0에서 1 사이로 바꿔준다.

💡
N2N Sequence Labelling을 허깅페이스를 사용해서 수행하자(w.KLUE-DP 데이터셋)
- 선학습된 BERT 아키텍쳐를 사용했다. (bert-base-multilingual-cased Config와 Tokenizer을 활용)
- loss func는 CrossEntropyLoss 사용
[코드]
- load_tsv 함수: KLUE DP 데이터셋에 맞게 character sequence, BIO label sequence를 생성
💡
N2M AutoModelForSeq2SeqLM 모델을 사용해서 날짜 정규화를 해보자 (w.다양한 형태의 날짜 데이터셋)
- 입출력 디자인을 위해서 Huggingface AutoTokenizer 사용
- 선학습되지 않은 BART 아키텍쳐를 활용했다. (facebook/bart-base Config와 Tokenizer을 활용)
# 페이스북 bart-base 모델의 설정값 불러오기 - 구조만 가져옴
self.config = transformers.BartConfig.from_pretrained('facebook/bart-base')
# 불러온 설정값을 토대로 AutoModelForSeq2SeqLM(BART) 모델 생성
self.encoder_decoder = transformers.AutoModelForSeq2SeqLM.from_config(self.config)
- loss func는 CrossEntropyLoss 사용
- WandB sweep을 활용해 하이퍼파라미터 튜닝
