S2S, PyTorch Lightning
<목차>
1. Sequence 2 Sequence Learning (S2S)
2. PyTorch Lightning
- MNIST 실습
<요약>
현대 자연어처리 기술을 크게 세가지 형태의 문제로 정리할 수 있습니다.
입력과 출력의 형태에 따라 N21, N2N 그리고 N2M 세가지 형태로 나누어보고,
각 문제의 형태마다 1) 대표적인 자연어처리 문제 소개, 2) 대표적인 구현방식, 3) 평가 방법 그리고 4) 실습 을 진행합니다.
최근 자연어처리 기술은 과거처럼 각 문제를 잘 풀어내는 신경망 구조 연구(Architecture Engineering) 보다는 Transformer와 같은 공통된 하나의 대규모 신경망을 어떠한 데이터에 이용하여 대해 어떠한 문제를 통해 훈련시키는가, 그리하여 최종적으로 얼마나 목표문제를 잘 해결하는 표현학습(Representation Learning)를 이루어 낼 수 있는지가 더더욱 중요해지고 있습니다.
NLP Tasks

Sequence 2 Sequence Learning (S2S)
입력과 출력 사이에 Sequence 2 Sequence Learning (S2S) 엔진이 있다
S2S는 특정한 기술이나 테크닉을 일컫는 것이 아니라 '이런 식으로 문제를 정의하자'는 프레임 워크이다.

현 시점에서 가장 성능이 좋고 범용적인 신경망 구조는 Transformer이므로 앞으로는 S2S의 기본 Encoder, Decoder로 가정하겠다.
| N21 | ex 1. 주제 분류(Topic Classification) : 하나의 문장이 입력되고 주제들이 Class token(CLS)로 출력된다.  2. 의미 유사성(Semantic Textual Similarity) : token SEP는 두 문장의 입력을 구분하고, 0~(최대 점수) 사이의 점수가 CLS에 출력된다. 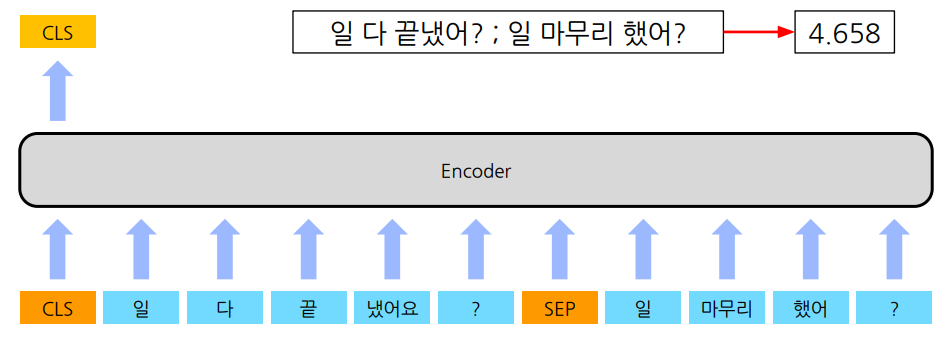 3. 자연어 추론(Natural Language Inference, NLU) : 가설 문장과 전제 문장의 관계를 추론한다. 진실(entailment), 거짓(contradiction), 미결정(neutral)이 CLS에 출력된다.  |
| N2N | ex 1. 개체명 인식 (Named Entity Recognition) : 구조화되지 않은 텍스트에서 개체명의 경계를 감지하고 유형을 분류한다. 개체명은 미리 정의해두고, Token 별로 개체 명의 Label 이 출력된다. 2. 형태소 분석(Morphology Analysis) : 입력되는 텍스트의 최소 형태소 단위를 찾는다. 형태소란 문장을 구성하는 최소의 단위이다.  |
| N2M | - 확장성이 좋다. - decoder, generation(생성)하는 것이 중요하다. ex 1. 기계 번역(Machine Translation)  2. 대화 시스템(Dialogue Model)  3. 요약(Summarization) : extract, abstract 두 가지로 나뉜다. extract는 발췌 중심, abstract는 기계가 의미를 추상화 시켜서 내용을 완전히 이해하고 요약한다. 4. Image Captioning : 이미지를 통해 설명하는 caption(설명)을 만들어낸다.  |
PyTorch Lightning
PyTorch Lightning은 PyTorch에 대한 High-level 인터페이스와 더 높은 수준의 자동화 기능을 제공한다.
복잡한 PyTorch 코드들을 추상화함으로써 다루고 싶은 문제들에만 집중할 수 있게 한다는 장점이 있다.
Keras
더 높은 수준의 직관적인 추상화 집합을 표현함으로써 신경망을 구성하기 쉽게 만들어준다.

Keras VS PyTorch Lightning
자동화 기능이라는 공통점이 있다

PyTorch Lightning을 사용해 Deep Learning Process 코드를 살펴보자
Deep Learning Process는 크게 Data Preparation, Model Implementation, Loss Implementation, Updater Implementation, Iterative Iearning의 단계로 나눠진다.
| Data Preparation | 입출력 데이터를 담는 Tensor을 생성 1.  👇  prepare_data()로 데이터 다운로드, setup() 으로 데이터 분할 prepare_data()는 process에서 한 번 호출되고, setup()은 gpu마다 호출하여 처리한다. 2. Data를 batch로 쪼갤 때  |
| Model Implementation | 신경망 학습을 위한 모델 구현 1.  👇  2. Optimizer  optimizer을 별도로 생성하고 학습 시 호출한다. 즉, configure_optimizers() 안에 생성하고 Train step이 끝날 때마다 자동으로 호출한다. |
| Loss Implementation | 모델이 얼마나 틀렸는 지를 측정하는 함수 설정 1. Test & Loss  2. Validation & Loss  3. Test & Loss  |
| Updater Implementation | 초기에 설정된 가중치에서 최적의 가중치로 옵티마이저를 구현 |
| Iterative Iearning | 데이터 Feeding을 통한 모델 반복 학습 및 검증 |
Torch Metrics
아래와 같은 다양한 metric을 제공한다. metric이란 우리가 대시보드를 볼때 특정 수치들을 그래프로 보여주는 일종의 시각화를 의미한다.

💡
[실습] MNIST 데이터를 학습하는 PyTorch, PyTorch Lightning 코드 비교
PyTorch의 random_split은 55000개의 Train Dataset을 Train 50000개, Validation 5000개로 알아서 쪼개준다.
from torch.utils.data import DataLoader, random_split
mnist_train, mnist_val = random_split(mnist_train, [55000, 5000])
!pip install pytorch-lightning
import pytorch_lightning as plPyTorch Lightning의 Model Implement 작업에서 클래스 안에 들어가는 함수에는
validation_step와 validation_epoch_end가 있다.
def validation_step(self, batch, batch_idx):
data, target = batch
output = self(data)
## loss calculation : 매 batch의 손실값 계산
loss = F.nll_loss(output, target)
pred = output.argmax(dim=1, keepdim=True)
correct = pred.eq(target.view_as(pred)).sum().item()
return {"val_loss" : loss, "correct" : correct}
def validation_epoch_end(self, outputs): # 전체 batch data의 손실값 계산
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
self.log('val_loss', avg_loss)
self.log('avg_val_loss', avg_loss)
Train과 Validation의 step은 batch 단위이기 때문에
validation_step에서는 매번 batch의 loss 값을 계산하고(step별로), validation_epoch_end에서는 전체 batch data의 손실값을 계산한다. (epoch 별로)
- Optimzer : loss function의 최솟값을 찾는 과정인 '최적화'를 수행하는 알고리즘
- Scheduler : 학습 과정에서 lerning rate를 조정하는 역할을 한다.
아래 코드와 같이 optimzer와 scheduler을 정의한다.
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
scheduler = StepLR(optimizer, step_size=1)
Q. 모델로부터 학습할 때, 우리는 Optimizer와 Scheduler을 사용합니다. 어떤 Optimizer와 Scheduler가 있고 무슨 경우 사용하는게 좋을까요?
A. 아래와 같은 다양한 Optimizer가 있다.

