Sequential Models - Transformer
Sequential model의 한계점과 이를 해결 하기 위해 등장한 Transformer
Transformer는 Encoder와 Decoder로 구성되어있지만 강의에서는 Encoder와 Multi Head Attention 에 대해 좀 더 집중적으로 배웁니다.
<목차>
1. Transformer
- self attention
- Multi-headed attention (MHA) : Positional Encoding
2. Vision Transformer
3. DALL- E
Sequential model의 한계점
data가 중간에 빠져 있거나 순서가 달라지면 모델링하기 어려움
Transformer
- first sequence transduction model based entirely on attention
- 재귀적인 구조가 없음. attention이라는 구조를 활용함 <-> RNN은 재귀적으로 돌아감
sequence - sequence model : 프랑스어 문장을 영어로 바꿈
입력 sequence, 출력 sequence 숫자가 다를 수 있음/ domain도 다를 수 있음
self attention (encoder)에서는 한 번에 찍음
<-> RNN은 세 개의 단어가 들어가면 세 번 nn이 돌아감.
** N개의 단어가 어떻게 한 번에 처리되는 지, 인코더와 디코더 사이 어떤 정보 주고 받는 지 중요, 디코더가 어떻게 generation 할 수 있는 지 **
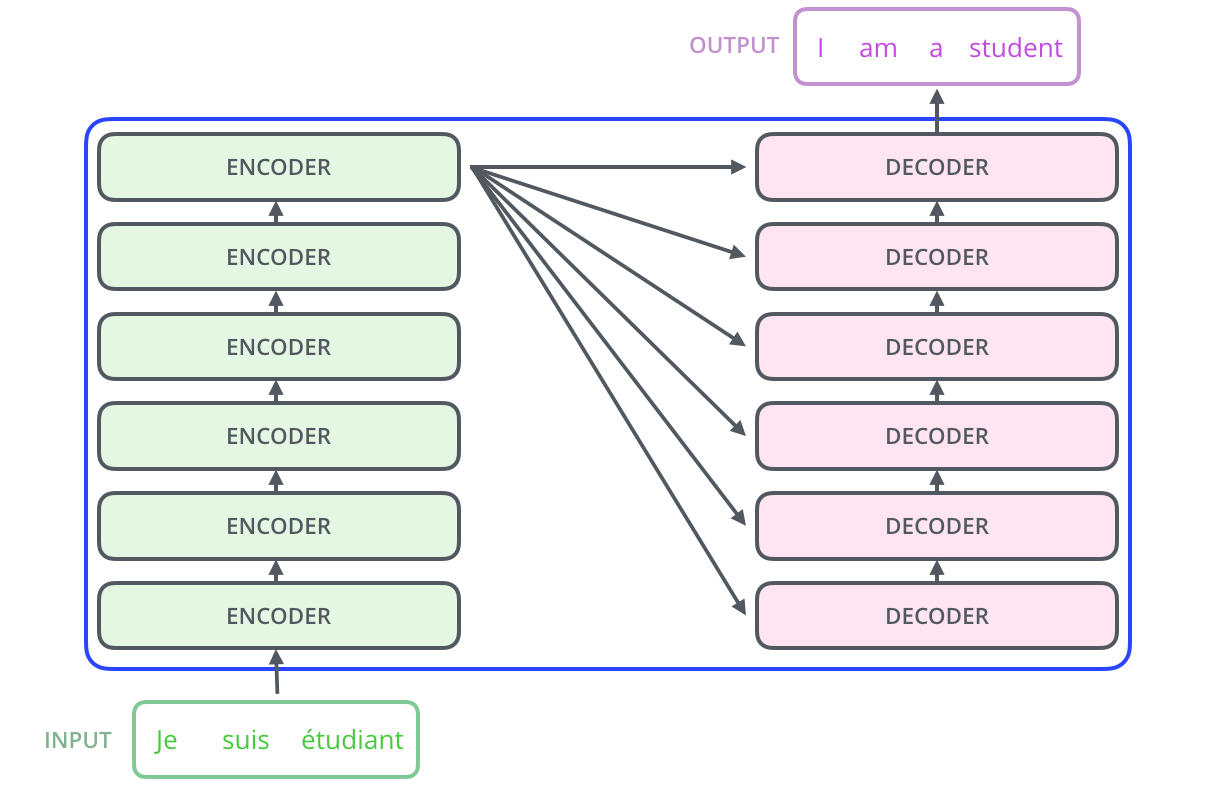
인코더: 표현 / 디코더: 생성
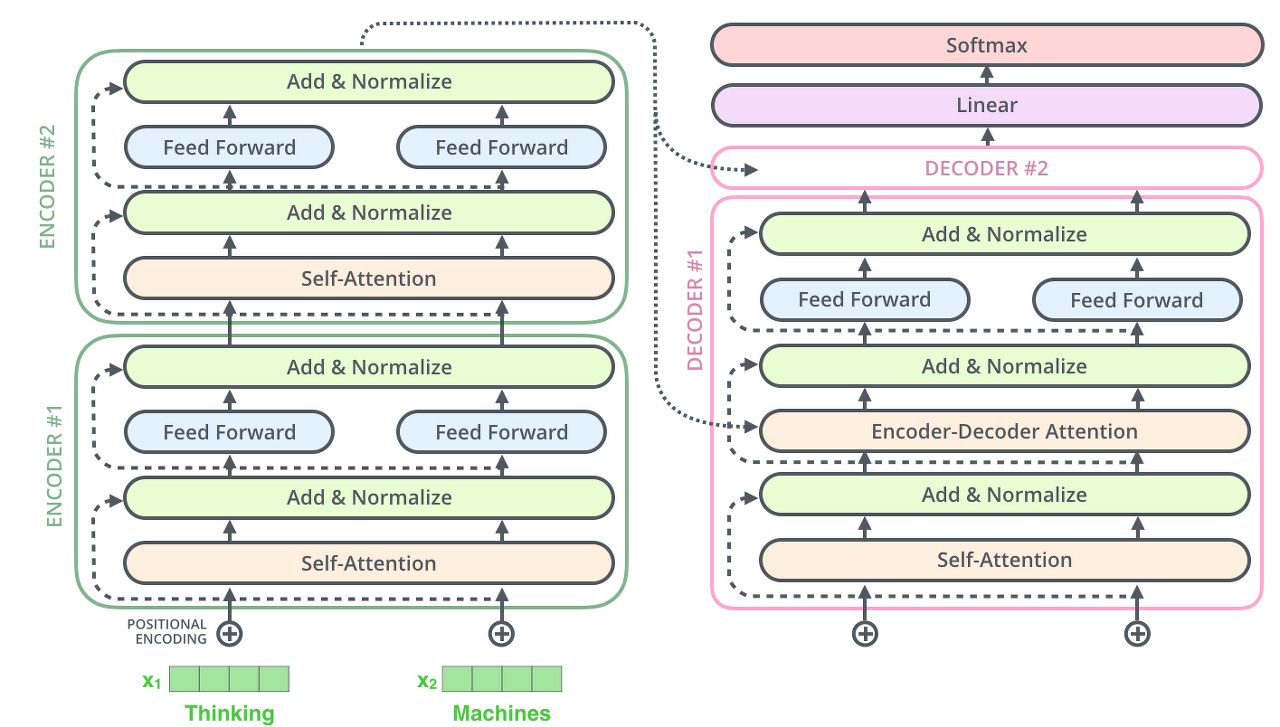
encoding 부분은 여러 개의 encoder를 쌓아 올려 만든 것 (논문에서는 6개를 쌓았다고 합니다만 꼭 6개를 쌓아야 하는 것은 아니고 각자의 세팅에 맞게 얼마든지 변경하여 실험할 수 있음).
decoding 부분은 encoding 부분과 동일한 개수만큼의 decoder를 쌓은 것. encoder들은 모두 정확히 똑같은 구조를 가지고 있음 (그러나 그들 간에 같은 weight을 공유하진 않음).
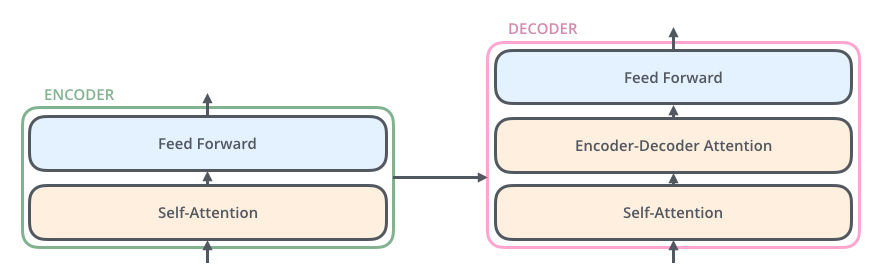
- 인코더에 들어온 입력은 일단 먼저 self-attention layer을 지나가게 됨. 이 layer 은 encoder가 하나의 특정한 단어를 encode 하기 위해서 입력 내의 모든 다른 단어들과의 관계를 살펴봄. 입력이 self-attention 층을 통과하여 나온 출력은 다시 feed-forward 신경망으로 들어가게 됨. 똑같은 feed-forward 신경망이 각 위치의 단어마다 독립적으로 적용돼 출력을 만듦.
- decoder 또한 encoder에 있는 두 layer 모두를 가지고 있음. 그러나 그 두 층 사이에 seq2seq 모델의 attention과 비슷한 encoder-decoder attention이 포함되어 있음. 이는 decoder가 입력 문장 중에서 각 타임 스텝에서 가장 관련 있는 부분에 집중할 수 있도록 함.

Self Attention 살펴보기
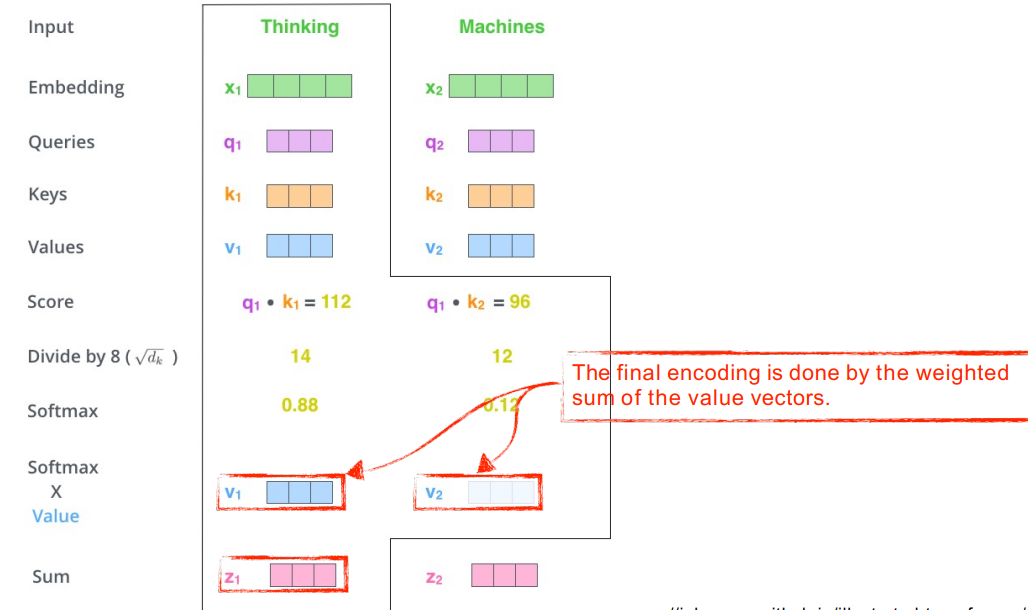
- self attention 구조는 세 가지 벡터 query, key, values를 만들어냄 (3개의 Neural network라고 이해)
- score 벡터를 만듦 (인코딩 하고자 하는 쿼리 벡터와 나머지 모든 키 벡터를 내적. i번째 단어가 나머지 단어와 얼마나 유사도 있는 지 확인)


- score 벡터를 8로 나눠서 normalize (key벡터가 몇 차원으로 만들어지느냐)
- softmax를 취해서 0~1 사이의 값으로 attention weight을 계산 (자기 자신 혹은 다른 단어와 얼마냐 interaction 해야하는가. 스칼라값)
- -> value 벡터로 가짐 (각 단어의 embedding에서 나오는 value벡터의 weight sum이 최종적으로 필요한 값)

<주의 할 점>
1) 쿼리벡터와 키 벡터는 차원이 항상 같아야함 (이유: 내적해야해서)
2) 쿼리벡터와 키 벡터는 value 벡터와 차원이 달라도 됨 (이유: weighted sum만 하면 되니까)
3) 최종적으로 나오는 encoding된 벡터의 차원은 value 벡터의 차원과 동일
Self Attention의 matrix 계산
위의 내용을 행렬로 간단하게 표현 : X로부터 나온 Q, K, V를 계산해서 Z를 찾움


Transformer의 장점
- 고정된 이미지를 CNN이나 MLP에 넣으면 결과가 고정되어있음. 그러나 Transformer는 인코딩 하려는 옆 단어에 따라 결과 달라지므로 flexible하다는 장점이 있음.
Transformer의 단점
- 많은 computation이 필요하다는 단점이 있음.
- N개의 단어가 주어지면 N x N짜리 attention map을 만들어야함. (<-> RNN은 1000개의 sequence가 주어지면 1000번 돌리기만 하면 됨) -> 처리할 수 있는 한계가 있음
Multi-headed attention (MHA)
- allows Transformer to focus on different positions.
- 하나의 입력(임베딩된 벡터)에 대해 query, key를 하나만 만드는 게 아니라 여러 개 만듦
임베딩이란 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 또는 그 과정을 의미함
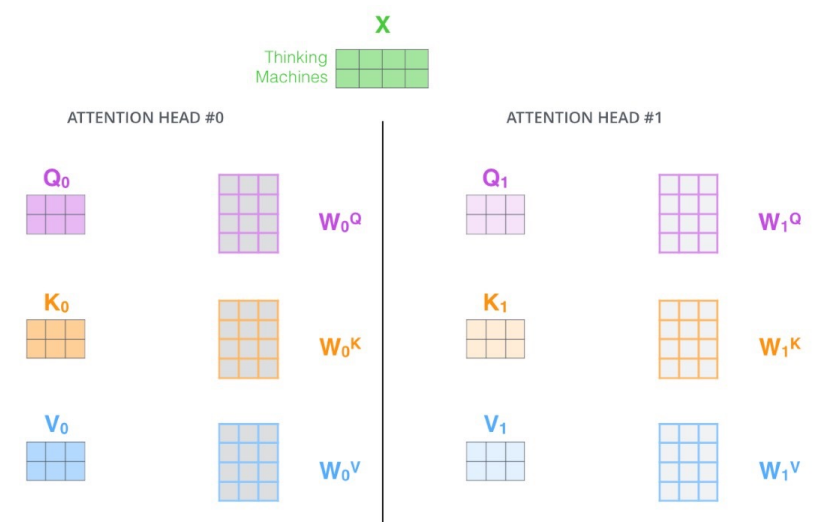
N개의 Attention을 하면 N개의 encoding 벡터가 나올 것임.
위 그림의 경우 8개의 Head가 사용되었으므로 8개의 encoding 벡터가 생성됨.

- 고려해야할 것: 입력과 출력의 차원을 맞춰줘야함. 즉, Embedding된 dimension과 Encoding되어서 self-attention 값으로 나오는 벡터의 dimension이 같아야 함.
- We simply pass them through additional (learnable) linear map. 일단 모두 이어 붙여서 하나의 행렬로 만들어버리고, 그다음 하나의 또 다른 weight 행렬인 W0을 곱해버림.

근데 실제 구현체를 보면 이렇게 되어있지 않다. (늘렸다가 줄이는 게 아니라, 나눈다.)
원래 내 embedding dimension이 100이라고 하고, 10개의 head를 사용한다면, 100 dimension을 10개로 나눈다.
즉, 실제로 Query, Key, Value 벡터를 만들 때 각각 10 dimension을 이용한다. (쪼개서 처리하고 concatenate 한 후에 dense layer에 처리)

Positional Encoding

- Positional Encoding 을 이용해서 시퀀스의 순서 나타내기 : Transformer 모델은 각각의 입력 embedding에 “positional encoding”이라고 불리는 하나의 벡터를 추가. 이 벡터들은 모델이 학습하는 특정한 패턴을 따르는데, 이러한 패턴은 모델이 각 단어의 위치와 시퀀스 내의 다른 단어 간의 위치 차이에 대한 정보를 알 수 있게 해줌.
- 이유: Transformer에 n개의 단어를 Sequential하게 넣어주었다고 하지만 사실 Sequential한 정보가 포함되어 있지는 않다. Self-Attention의 동작을 생각해보면 ABCDE를 넣거나 BCEDA를 넣거나 각각의 Encoding 값은 달라지지 않는다. 그러나 실제 문장을 만들때는 어떤 단어가 어디서 나오는지 순서가 중요하다. 그래서 positional encoding 값을 더해준다.
- 즉, 이 값들을 단어들의 embedding에 추가하는 것이 query/key/value 벡터들로 나중에 투영되었을 때 단어들 간의 거리를 늘릴 수 있게 함
<요약>
- Transformer transfers key (K) and value (V) of the topmost encoder to the decoder

- encoder가 입력 시퀀스 처리. encoder의 출력은 attention 벡터인 k와 v로 변형됨-> 이 벡터들은 각 decoder의 encoder- decoder attention layer(인코더와 디코더 사이의 interaction)에서 디코더가 입력 시퀀스에서 적절한 장소에 집중할 수 있도록 함
인코더와 디코더 사이 어떤 정보 주고 받는 가: Key와 Value 벡터
디코더가 어떻게 generation 할 수 있는 지
- decoding 단계에서 출력을 완료했다는 special 기호를 출력할 때까지 반복. encoder의 입력에 했던 것과 동일하게 embed를 한 후 positional encoding을 추가하여 decoder에게 각 단어의 위치 정보를 더함.
- decoder에서 self-attention layer은 마스킹을 통해 이전 단어들만 dependent하게 함(encoder와 다르게 동작)
이유: 학습 단계에서는 정답을 알게 되면 의미가 없기 때문에 뒤에 단어들은 dependent하지 않게
- decoder의 encoder- decoder attention layer은 Query 행렬들을 그 밑의 layer에서 가져오고 Key 와 Value 행렬들을 encoder의 출력에서 가져온다는 것 제외 multi-head self-attention과 똑같이 작동함.
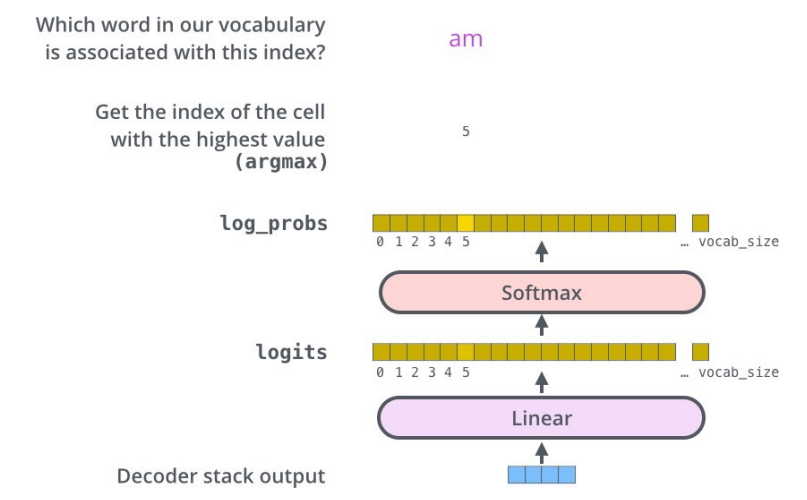
- 여러 개의 decoder를 거치고 난 후에는 소수로 이루어진 벡터 하나가 남음. 이 벡터를 단어로 바꾸는 게 Linear layer 과 Softmax layer가 하는 일
- Linear layer은 fully-connected 신경망으로 decoder가 마지막으로 출력한 벡터를 그보다 훨씬 더 큰 사이즈의 벡터인 logits 벡터로 투영시킴 ( 우리의 모델이 training 데이터에서 총 10,000개의 영어 단어를 학습하였다고 가정하면 logits vector의 크기는 10,000이 될 것임. 벡터의 각 셀은 그에 대응하는 각 단어에 대한 점수 )
- softmax layer는 이 점수들을 확률로 변환해주는 역할. 들의 변환된 확률 값들은 모두 양수 값을 가지며 다 더하게 되면 1이 되고, 가장 높은 확률 값을 가지는 셀에 해당하는 단어가 해당 스텝의 최종 결과물로서 출력
문장, 단어 처리 <->
Vision Transformer
이미지 분류에 인코더만 사용. 인코더에서 나오는 첫번째 벡터를 classifier에 집어넣는 식
이미지를 영역으로 나누고 하나의 입력처럼

DALL-E
문장을 주어지면 관련 이미지를 만듦
디코더만 활용을 함

