AI TECH
Computer Vision: segmentation, detection
prefer_all
2022. 10. 6. 11:25
<목차>
1. Semantic Segmentation
- convolutionalization VS Deconvolution
2. Object detection
- RCNN
- SPPNet
- Fast RCNN, Faster RCNN, RPN
- YOLO
Semantic Segmentation

- 이미지를 픽셀마다 분류하는 문제
- 이미지 안에 다양한 픽셀들을 각자 레이블로 분류함


- convolutionalization: dense 부분 없애고 conv로 바꾸자
- flat하고 dense 하는 거랑 conv로 바꾸는 거 param 개수 같음. 왜 할까?
- 원래는 결과가 확률분포 식으로 단순 분류만 할 수 있었다면 이제는 히트맵에 분포가 나오게 됨 -> segmentation 가능

- Deconvolution (convo transpose) : convolution의 역 연산
- convolution 하면 dimension이 줄어듦 5 x 5 -> 2 x 2
- deconvolution 하면 dimension이 늘어낢 2 x 2 -> 5 x 5
- 엄밀하게는 convolution의 역연산이라는 건 없음 (10이라는 숫자가 뭐로 만들어졌는 지 알 수 없음)
- 나머지 부분을 다 padding으로 만듦


Detection
- 이미지 안에서 어느 물체가 어디있는가 (per pixel이 아니라 bounding box)
- RCNN :
- 이미지 안에서 패치 (지역)을 뽑음 (selective search) -> 똑같은 크기로 맞춤 -> 분류
- 이미지 가져와서 이미지 안에서 사물인 것 같은 지역 2000개 뽑음
- AlexNet으로 각 지역에 대한 feature 계산
- linear SVM으로 분류
- (문제) 지역에 대해 모두 CNN 돌림
- 이미지 안에서 패치 (지역)을 뽑음 (selective search) -> 똑같은 크기로 맞춤 -> 분류

- SPPNet
- 이미지 안에서 CNN 한 번만 돌림
- 이미지 안에서 bounding box 뽑고 이미지 전체에 대해 feature map 만들어 뽑힌 위치에 해당하는 tensor만 긁어옴

- Fast RCNN
1) 입력 이미지로 bounding box 뽑음
2) CNN 한 번 돌려서 convolutional feature map 생성(SPPNet과 동일)
3) 각 지역에 대해 고정 길이 feature를 ROI pooling으로부터 얻음
4) 클래스와 바운딩 박스 regressor 두 결과를 얻어냄 (NN을 통해서 바운딩 박스를 어떻게 움직이면 좋을 지, 바운딩 박스의 라벨을 찾게 됨)

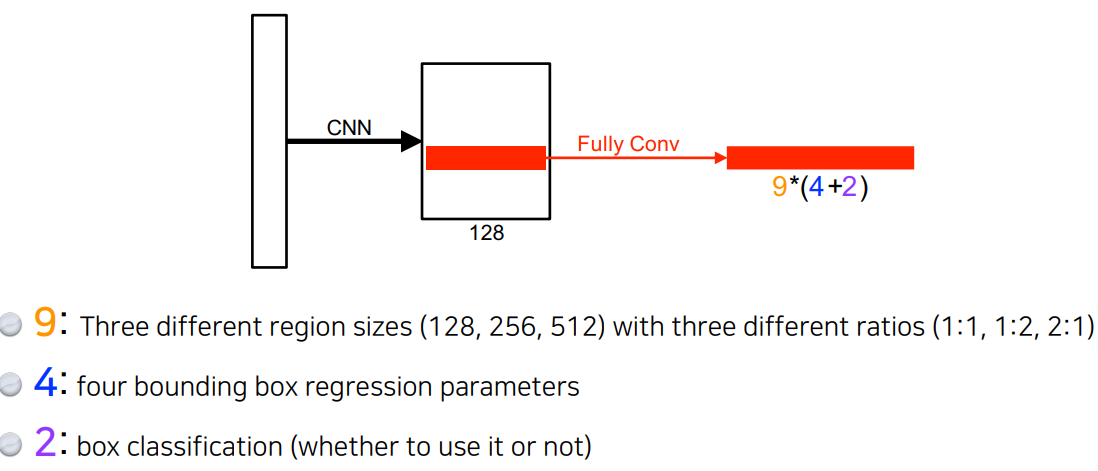
- Faster RCNN
- 이미지를 통해 bounding box를 뽑아내는 region proposal도 학습 시키자

- Region Proposal Network (RPN)
- 어떤 이미지를 주면 어떤 지역 안에 물체가 있을 지 판단 - 무엇인지는 안 찾음
- anchor boxes: 어떤 크기들의 물체들이 있을 지 미리 아는 템플렛. 미리 정해둔 크기

- YOLO (You Only Look Once)
- 아주 빠른 object detection algorism/ baseline: 45fps / smaller version: 155fps
- simultaneously predicts multiple bounding boxes and class probabilities
- RPN을 사용하는 게 아니라 이미지를 한 번에 바로 체크 No explicit bounding box sampling
- 과정
- 이미지가 들어오면 S x S 그리드로 나눔 / 물체를 바운딩 박스로 감지 + 분류 확률에 비춰봄 -> 바로 결과 나옴
- 각 셀은 B = 5 개의 바운딩 박스를 예측함. 그 바운딩 박스들이 box probability를 통해 쓸모 있는 지 없는 지 확인, box refinement와 confidence check를 이용 / (그와 동시에) 각 셀은 C class probabilities를 예측함
- 두 정보를 취합해 박스 + 클래스를 알게 됨

- tensor의 크기는 S x S x (B*5+C)
- SxS: Number of cells of the grid
- B*5: B bounding boxes with offsets (x,y,w,h) and confidence
- C: Number of classes
